A Priori vs A Posteriori Dietary Pattern Analysis: A Comprehensive Guide for Biomedical Researchers
This article provides a comprehensive overview of the two principal methodologies in dietary pattern analysis for researchers and drug development professionals.
A Priori vs A Posteriori Dietary Pattern Analysis: A Comprehensive Guide for Biomedical Researchers
Abstract
This article provides a comprehensive overview of the two principal methodologies in dietary pattern analysis for researchers and drug development professionals. It covers the foundational concepts of a priori (hypothesis-driven) and a posteriori (exploratory, data-driven) approaches, detailing their statistical methods, applications, and limitations. The content explores how these patterns are validated against health outcomes like Parkinson's disease, gastric cancer, and hypertension, and offers guidance for method selection and troubleshooting common analytical challenges. By synthesizing current evidence, this guide aims to inform robust study design in nutritional epidemiology and the development of targeted dietary interventions.
Understanding the Core Concepts: A Priori and A Posteriori Dietary Patterns
In scientific research, particularly within nutritional epidemiology and systems biology, two fundamental paradigms guide inquiry: hypothesis-driven and data-driven approaches. These methodologies represent distinct philosophical frameworks for generating knowledge. The hypothesis-driven approach, aligned with a priori reasoning, begins with a specific, pre-defined prediction derived from existing theory. In contrast, the data-driven approach, operating through a posteriori analysis, seeks to identify patterns and generate hypotheses directly from comprehensive datasets without initial presuppositions about outcomes [1]. This dichotomy frames a critical methodological tension in contemporary science, especially evident in studies investigating complex relationships between dietary patterns and health outcomes.
The distinction between these paradigms extends beyond mere procedural differences to encompass fundamental questions about how scientific knowledge should be constructed and validated. While some position these approaches as opposing ideologies [2], they are more productively viewed as complementary components of the scientific enterprise, each with distinctive strengths, limitations, and appropriate applications within the research lifecycle.
Conceptual Foundations and Definitions
Hypothesis-Driven Research (A Priori Approach)
Hypothesis-driven research follows a deductive logic structure, beginning with a specific, testable prediction derived from theoretical frameworks or previous observations. This a priori methodology employs a top-down approach where researchers formulate hypotheses before data collection and design experiments specifically to test these predetermined questions [1]. The process follows a structured sequence: existing knowledge → hypothesis formulation → targeted experiment design → data collection → hypothesis testing → conclusion.
In nutritional science, a classic example of this approach would involve investigating whether a specific micronutrient (e.g., vitamin D) affects bone density in elderly populations. Researchers would design a controlled trial with precise measurements of vitamin D intake and bone density outcomes, collecting only the data necessary to test their specific hypothesis about this relationship.
Data-Driven Research (A Posteriori Approach)
Data-driven research operates through inductive reasoning, beginning with comprehensive data collection without specific pre-formed hypotheses. This a posteriori methodology utilizes a bottom-up approach where researchers gather extensive datasets first, then apply analytical techniques to identify patterns, relationships, and potential hypotheses that emerge from the data itself [1] [2]. The sequence reverses: comprehensive data collection → pattern recognition → hypothesis generation → further testing.
A prominent example in modern nutritional epidemiology involves using metabolomics to analyze thousands of compounds in blood samples from large population cohorts. Without presupposing which metabolites might be important, researchers apply computational methods to discover which compounds correlate with disease states, thereby generating new hypotheses about metabolic pathways involved in disease pathogenesis [3].
The False Dichotomy
The purported tension between these approaches represents what some scholars term a "false dichotomy" [2]. In practice, robust research programs often integrate both methodologies at different stages of investigation. Data-driven exploration frequently identifies novel relationships that subsequently form the basis for precise hypothesis testing, while hypothesis-driven findings may open new avenues for broad exploratory analysis. The most impactful science typically occurs through iterative cycles between these modes rather than exclusive adherence to one paradigm.
Methodological Frameworks in Dietary Pattern Research
The distinction between a priori and a posteriori approaches finds particular relevance in nutritional epidemiology, specifically in the study of dietary patterns and disease relationships. These methodologies offer complementary approaches to understanding how overall eating patterns influence health outcomes.
A Priori Dietary Pattern Analysis
A priori dietary patterns are defined based on existing scientific knowledge, dietary guidelines, or theoretical frameworks about what constitutes a healthy or harmful diet. Researchers pre-specify scoring systems based on current understanding of nutritional science, then apply these predetermined patterns to study participants' dietary data.
Key Methodological Characteristics:
- Pre-defined scoring systems based on existing knowledge
- Hypothesis-testing orientation examining specific dietary theories
- Reduction of multidimensional data into single scores or indices
- Theoretical foundation in nutritional science and epidemiological evidence
Common A Priori Indices:
- Mediterranean Diet Score: Assesses adherence to traditional Mediterranean eating patterns characterized by high consumption of fruits, vegetables, nuts, legumes, whole grains, and olive oil; moderate consumption of poultry, fish, and alcohol; and low consumption of red and processed meats [4].
- Healthy Eating Index (HEI-2010): Measures alignment with national dietary recommendations, evaluating adequacy of beneficial food groups and moderation of potentially harmful components [3].
- Dietary Approaches to Stop Hypertension (DASH): Scores adherence to a dietary pattern specifically designed to reduce blood pressure.
A recent meta-analysis of observational studies demonstrated the utility of this approach, finding that adherence to the Mediterranean diet was associated with a statistically significant 13% reduction in Parkinson's disease risk (RR = 0.87; 95%CI: 0.78–0.97), while healthy dietary patterns showed even stronger protective associations (RR = 0.76; 95%CI: 0.65–0.91) [4].
A Posteriori Dietary Pattern Analysis
A posteriori dietary patterns emerge empirically from the dietary data of the study population itself, using statistical techniques to identify common combinations of foods actually consumed by participants. These data-driven patterns are derived without pre-specified theoretical frameworks about what constitutes a healthy diet.
Key Methodological Characteristics:
- Patterns emerge from data rather than pre-defined theory
- Hypothesis-generating orientation discovering naturally occurring dietary combinations
- Multivariate statistical techniques to reduce dimensionality
- Population-specific patterns that reflect actual consumption habits
Common Statistical Techniques:
- Factor Analysis (Exploratory): Identifies underlying constructs (factors) that explain correlations between food groups.
- Principal Component Analysis (PCA): Creates linear combinations of original food variables that capture maximum variance.
- Cluster Analysis: Groups individuals into distinct dietary patterns based on similarity of food intake profiles.
A study of the American Gut Project demonstrated the power of this approach, identifying five distinct a posteriori dietary patterns that were more strongly associated with gut microbiome variations than individual dietary features [3]. These included two Prudent-like diets (Plant-Based and Flexitarian), two Western-like diets with different health consciousness gradients, and an Exclusion diet pattern, with the Flexitarian pattern showing significantly higher gut microbiome alpha diversity compared to the most Western pattern.
Table 1: Comparison of A Priori and A Posteriori Dietary Pattern Methodologies
| Characteristic | A Priori Approach | A Posteriori Approach |
|---|---|---|
| Theoretical basis | Based on pre-existing knowledge or theory | Derived empirically from data |
| Hypothesis relationship | Tests specific hypotheses | Generates new hypotheses |
| Pattern definition | Pre-defined scoring systems | Statistically derived patterns |
| Primary techniques | Index scores based on guidelines | Factor analysis, PCA, cluster analysis |
| Key advantage | Grounded in established science | Reflects actual population eating patterns |
| Main limitation | Constrained by current knowledge | Population-specific, difficult to compare |
| Interpretation | Straightforward based on predefined criteria | Requires statistical and subject matter expertise |
Experimental Protocols and Methodologies
Protocol for A Priori Dietary Pattern Analysis
Study Design and Participant Selection:
- Cohort Definition: Establish clear inclusion/exclusion criteria for observational studies (cohort, case-control, or cross-sectional designs) [4].
- Sample Size Calculation: Conduct power analysis based on expected effect sizes and outcome incidence.
- Ethical Compliance: Obtain institutional review board approval and participant informed consent.
Dietary Assessment Methods:
- Data Collection: Administer validated food frequency questionnaires (FFQs), 24-hour dietary recalls, or food diaries.
- Nutrient Calculation: Use standardized food composition databases to estimate nutrient intakes.
- Quality Control: Implement procedures to ensure data completeness and accuracy, including range checks and cross-verification.
Dietary Pattern Construction:
- Index Selection: Choose appropriate a priori indices (e.g., Mediterranean Diet Score, HEI) based on research question.
- Component Definition: Define food group components and scoring criteria according to established protocols.
- Score Calculation: Compute individual adherence scores for each participant based on their dietary data.
Statistical Analysis:
- Model Specification: Employ multivariable regression models (Cox proportional hazards for cohort studies, logistic regression for case-control) adjusting for relevant confounders (age, sex, BMI, physical activity, smoking, education).
- Dose-Response Assessment: Test for linear trends across quartiles or quintiles of dietary pattern adherence.
- Sensitivity Analysis: Conduct stratified analyses to examine effect modification and assess robustness of findings.
Protocol for A Posteriori Dietary Pattern Analysis
Dietary Data Preparation:
- Food Grouping: Aggregate individual food items into meaningful food groups based on nutritional similarity and usage.
- Energy Adjustment: Apply appropriate energy adjustment methods (residual or density methods) to account for differences in total energy intake.
- Data Transformation: Normalize or standardize intake variables as needed for multivariate analysis.
Pattern Derivation:
- Factorability Assessment: Evaluate data suitability for factor analysis using Kaiser-Meyer-Olkin measure and Bartlett's test of sphericity.
- Factor Extraction: Apply principal component analysis or factor analysis to identify patterns based on correlation matrices.
- Factor Rotation: Use orthogonal (varimax) or oblique rotation to achieve simpler structure and enhance interpretability.
- Factor Retention: Determine number of patterns to retain using eigenvalues (>1.0), scree plot examination, and interpretability criteria.
- Factor Interpretation: Label derived patterns based on food groups with highest factor loadings (typically >|0.2| or >|0.3|).
Validation and Outcome Analysis:
- Internal Validation: Assess pattern stability through split-sample validation or bootstrapping techniques.
- Pattern Scores: Calculate factor scores for each participant representing their adherence to each derived pattern.
- Outcome Modeling: Examine associations between pattern scores and health outcomes using appropriate regression models with comprehensive confounding adjustment.
- Biological Plausibility: Interpret findings in context of existing biological knowledge and potential mechanisms.
Table 2: Key Quantitative Findings from Dietary Pattern and Disease Research
| Dietary Pattern | Study Design | Participants/Cases | Risk Estimate (RR/OR/HR) | 95% Confidence Interval |
|---|---|---|---|---|
| Mediterranean Diet | Meta-analysis (11 studies) | 326,751 / 2,524 | RR = 0.87 | 0.78–0.97 [4] |
| Healthy Dietary Index | Meta-analysis (11 studies) | 326,751 / 2,524 | RR = 0.76 | 0.65–0.91 [4] |
| Healthy Dietary Pattern | Meta-analysis (11 studies) | 326,751 / 2,524 | RR = 0.76 | 0.62–0.93 [4] |
| Western Dietary Pattern | Meta-analysis (11 studies) | 326,751 / 2,524 | RR = 1.54 | 1.10–2.15 [4] |
| Plant-Based Pattern | American Gut Project | 744 participants | Microbiome association | P ≤ 0.0002 [3] |
| Flexitarian Pattern | American Gut Project | 744 participants | Higher alpha diversity | P ≤ 0.009 [3] |
Visualization of Research Workflows
Hypothesis-Driven Research Workflow
Data-Driven Research Workflow
Integrated Research Approach
The Scientist's Toolkit: Essential Research Reagents and Solutions
Table 3: Essential Methodological Tools for Dietary Pattern Research
| Tool Category | Specific Tools/Techniques | Primary Function | Application Context |
|---|---|---|---|
| Dietary Assessment | Food Frequency Questionnaires (FFQ), 24-hour recalls, Food diaries | Capture comprehensive dietary intake data | Both a priori and a posteriori approaches |
| Statistical Analysis | Principal Component Analysis (PCA), Factor Analysis, Cluster Analysis | Derive empirical dietary patterns from consumption data | Primarily a posteriori approach |
| Index Construction | Mediterranean Diet Score, Healthy Eating Index (HEI), DASH Score | Quantify adherence to pre-defined dietary patterns | Primarily a priori approach |
| Microbiome Analysis | 16S rRNA sequencing, Metagenomics | Characterize gut microbial community composition | Outcome measurement in nutritional studies |
| Data Management | REDCap, Nutrition Data Systems | Standardized data collection and management | Both approaches |
| Statistical Software | R, Python, SAS, SPSS, STATA | Implement statistical analyses and modeling | Both approaches |
The dichotomy between hypothesis-driven and data-driven approaches represents a false binary that fails to capture the dynamic, iterative nature of scientific progress [2]. Rather than opposing methodologies, these approaches function most effectively as complementary phases within integrated research programs. The distinction between a priori and a posteriori reasoning provides a valuable philosophical framework for understanding how different methodological approaches contribute to knowledge construction in nutritional epidemiology and systems biology.
Future research should leverage the synergistic potential of both paradigms, using data-driven approaches to identify novel patterns and generate hypotheses in our increasingly data-rich research environment, while employing hypothesis-driven methods to rigorously test these insights through targeted experimentation. This integrative approach promises to accelerate scientific discovery while maintaining the methodological rigor necessary for reliable knowledge generation. As the technological capacity for data collection and analysis continues to expand, the most successful research programs will be those that strategically employ both paradigms throughout the knowledge generation cycle.
The Rationale for Dietary Pattern Analysis Over Single-Nutrient Studies
Traditional research in nutritional epidemiology has predominantly focused on the relationship between single nutrients or individual foods and health outcomes. However, a significant paradigm shift toward dietary pattern analysis has occurred, recognizing that humans consume foods and nutrients in combination, not in isolation [5] [6]. This shift responds to several critical limitations of the single-nutrient approach, including the phenomenon of multicollinearity (high intercorrelations between dietary components), the synergistic and antagonistic effects between nutrients, and the statistical challenges of detecting small effect sizes from individual dietary components amid multiple testing [6] [7]. Dietary pattern analysis offers a holistic alternative that captures the complexity of whole diets as actually consumed, providing a more comprehensive framework for understanding diet-disease relationships and developing effective public health recommendations [5] [8].
The following visual conceptualizes the fundamental limitations of the single-nutrient approach that necessitated this paradigm shift toward dietary pattern analysis.
Fundamental Rationale for Dietary Pattern Analysis
Capturing Dietary Synergy and Complexity
The fundamental premise of dietary pattern analysis is that cumulative and interactive effects among dietary components reflect the biological reality of human consumption patterns [6]. Nutrients and foods are not metabolized in isolation but interact in complex ways that can produce synergistic or antagonistic effects on health outcomes. For instance, the effect of salt on hypertension may be moderated by the potassium and sugar content of the diet, and the absorption of certain micronutrients can be enhanced or inhibited by other dietary components [9]. These intricate interactions are largely invisible to single-nutrient analyses but are central to understanding how diet truly influences health. Dietary pattern analysis preserves these multidimensional relationships, providing a more biologically plausible model for nutritional research [5].
Addressing Methodological Limitations
From a methodological perspective, dietary pattern analysis addresses several critical limitations of the single-nutrient approach. The problem of multicollinearity, where highly correlated dietary variables violate statistical assumptions in traditional regression models, is naturally accommodated within pattern analysis [6] [7]. Furthermore, by analyzing the overall diet, this approach reduces the problem of multiple comparisons and the associated risk of false-positive findings that occur when examining numerous individual nutrients [6]. Perhaps most importantly, dietary pattern analysis can account for the substitution effects inherent in human eating behavior, where consuming more of one food typically means consuming less of another [7]. This holistic perspective enables researchers to identify the net effect of overall dietary habits rather than isolated components.
Enhancing Public Health Translation
Dietary patterns are more easily translated into meaningful public health messages and dietary guidelines than recommendations about individual nutrients [6] [8]. While few people conceptualize their diet in terms of specific nutrients, most can understand recommendations about overall eating patterns such as "consume more fruits, vegetables, and whole grains" or "follow a Mediterranean-style diet" [6]. This translational advantage is significant for implementing effective nutrition interventions and policies. As evidence of this utility, food-based dietary guidelines worldwide have increasingly adopted pattern-based recommendations, emphasizing the quantities, proportions, and variety of foods and drinks typically consumed rather than focusing on isolated nutrients [8].
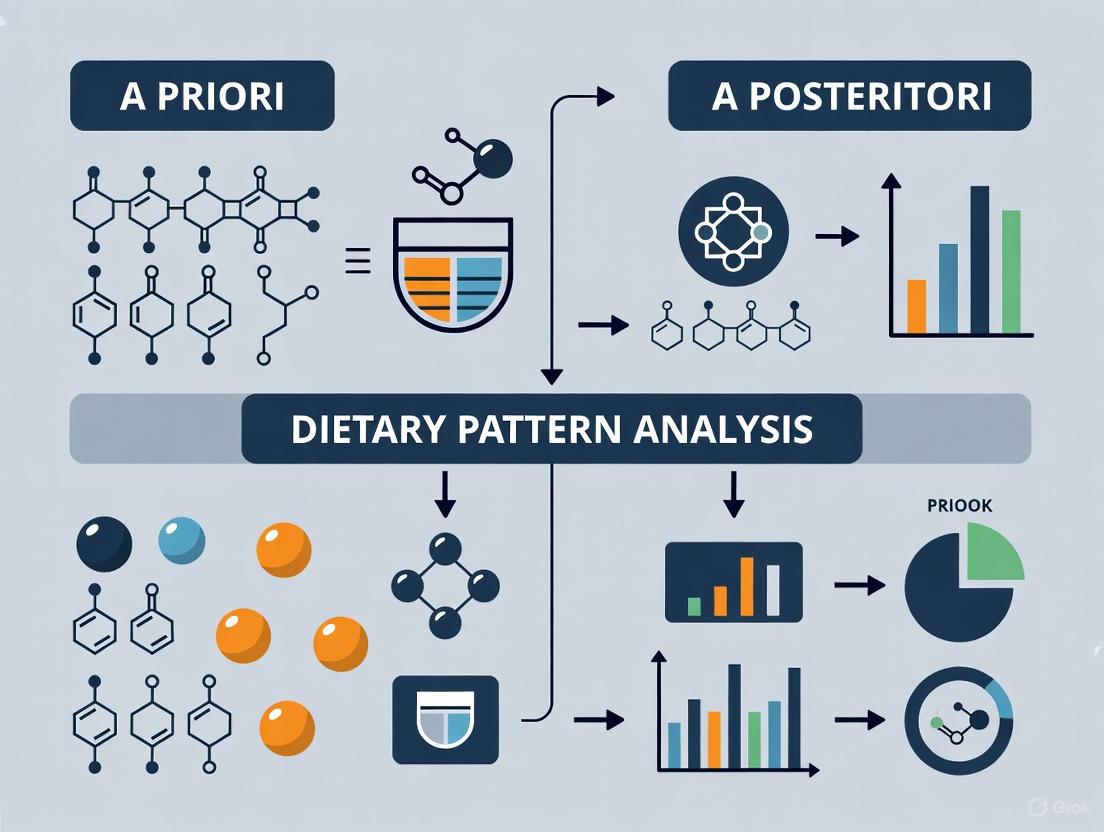
Methodological Approaches: A Priori vs. A Posteriori Analysis
Dietary pattern methodologies are broadly categorized into three distinct approaches, each with unique rationales, applications, and methodological considerations. The table below provides a comprehensive comparison of these approaches.
Table 1: Comparison of Dietary Pattern Analysis Methodologies
| Characteristic | A Priori (Hypothesis-Driven) | A Posteriori (Exploratory) | Hybrid Methods |
|---|---|---|---|
| Definition | Predefined scores based on existing nutritional knowledge or dietary guidelines [5] [6] | Patterns derived empirically from dietary intake data using statistical methods [5] [6] | Combines prior knowledge with data-driven techniques [5] [7] |
| Rationale | Assess adherence to "ideal" dietary patterns linked to health [6] | Describe actual dietary behaviors within a specific population [6] | Explain diet-health relationships via intermediate factors [5] |
| Common Examples | Mediterranean Diet Score (MDS), Healthy Eating Index (HEI), DASH score [5] [7] | Principal Component Analysis (PCA), Factor Analysis, Cluster Analysis [5] [7] | Reduced Rank Regression (RRR), Partial Least Squares [5] [7] |
| Key Strengths | Easily reproducible and comparable across studies [6]; Strong theoretical foundation [6] | Not limited by existing scientific knowledge [6]; Reveals actual population eating patterns [10] | Incorporates biological pathways; Stronger predictive power for specific diseases [5] [11] |
| Major Limitations | Subjectivity in component selection [6]; Limited by current nutritional knowledge [6] | Patterns may not represent healthy eating [6]; Subjective analytical decisions [6] | Limited by knowledge of intermediate biomarkers [5]; Complex interpretation [5] |
| Primary Applications | Monitoring diet quality; Evaluating dietary interventions [6] | Understanding population dietary habits; Identifying target groups for interventions [6] | Investigating biological mechanisms linking diet to disease [5] |
A Priori (Hypothesis-Driven) Methods
A priori methods operationalize predefined hypotheses about what constitutes a healthy or harmful dietary pattern. Researchers develop scoring systems, often called dietary indices or scores, that reflect adherence to specific dietary guidelines or culturally-defined eating patterns associated with health outcomes [5] [6]. The Mediterranean Diet Score (MDS), for instance, assesses conformity to traditional Mediterranean eating patterns characterized by high consumption of fruits, vegetables, whole grains, legumes, nuts, and olive oil, with moderate fish and poultry intake and low red meat consumption [5]. Similarly, the Healthy Eating Index (HEI) measures alignment with the Dietary Guidelines for Americans, while the DASH (Dietary Approaches to Stop Hypertension) score evaluates adherence to a dietary pattern specifically designed to reduce hypertension risk [5] [7].
The major advantage of a priori methods lies in their foundation in existing scientific evidence, making results interpretable within established theoretical frameworks and easily comparable across studies [6]. However, these methods are constrained by current nutritional knowledge and involve subjective decisions about which dietary components to include and how to score them [6]. Additionally, a priori scores developed in one population may not transfer effectively to others with different dietary cultures and food availability [11].
A Posteriori (Exploratory) Methods
In contrast to a priori approaches, a posteriori methods are data-driven and derive dietary patterns empirically from the dietary intake data of the study population without predefined hypotheses [5] [6]. These methods use multivariate statistical techniques to aggregate and reduce complex dietary data into a smaller set of patterns that explain the variation in eating behaviors within the population.
The most commonly used a posteriori methods include:
Principal Component Analysis (PCA) and Factor Analysis: These techniques identify patterns based on correlations between food items or food groups, creating composite variables (components or factors) that explain the maximum variation in dietary intake [7] [11]. Typically, these methods identify patterns such as "Western" (characterized by red meat, processed meat, refined grains, and high-fat dairy) and "Prudent" or "Healthy" (characterized by fruits, vegetables, whole grains, poultry, and fish) in Western populations [5].
Cluster Analysis: This method groups individuals into distinct clusters based on similarities in their overall dietary intake, resulting in categories such as "healthy eaters," "traditional consumers," or "convenience food consumers" [8].
The primary strength of a posteriori methods is their ability to reveal actual dietary behaviors within a population without being constrained by existing nutritional hypotheses [6] [10]. However, these methods involve numerous subjective decisions during analysis (e.g., how to group foods, how many patterns to retain) and resulting patterns may not necessarily represent healthy or unhealthy eating [6].
Hybrid and Emerging Methodologies
Hybrid approaches combine elements of both a priori and a posteriori methods. Reduced Rank Regression (RRR), the most prominent hybrid method, uses prior knowledge to select intermediate response variables (often biomarkers) related to a specific disease and then identifies dietary patterns that explain the maximum variation in these response variables [5] [11]. For example, RRR might use biomarkers like HbA1c, HOMA-IR, and fasting glucose as responses to derive a dietary pattern most predictive of diabetes risk [11].
Emerging methodologies continue to expand the analytical toolbox for dietary pattern analysis:
Treelet Transform (TT): Combines PCA and cluster analysis to produce patterns that involve smaller, naturally grouped variables, potentially enhancing interpretability [5] [11].
Data Mining and Machine Learning: Techniques such as decision trees and neural networks can identify complex, non-linear relationships in dietary data and reveal specific patterns associated with health outcomes [12] [13].
Compositional Data Analysis (CODA): Accounts for the relative nature of dietary data (where intake of one component affects others because total intake is constrained) by transforming data into log-ratios [7].
Network Analysis: Methods like Gaussian Graphical Models (GGMs) map complex webs of interactions and conditional dependencies between individual foods, capturing both linear and non-linear relationships [9].
The workflow below illustrates how these different methodological approaches are applied in dietary pattern research, from data collection to pattern interpretation.
Experimental Protocols and Analytical Frameworks
Standardized Protocols for Dietary Pattern Derivation
Regardless of the specific methodological approach, deriving dietary patterns follows a general sequence of analytical decisions. The process begins with dietary data collection, typically using Food Frequency Questionnaires (FFQs), 24-hour recalls, or food records [5]. Next, researchers engage in food grouping, aggregating individual food items into meaningful categories (e.g., "whole grains," "red meat," "low-fat dairy") based on nutritional similarity and culinary use [10]. Evidence suggests that using food groups rather than individual food items explains more variation in dietary intake and produces more stable patterns [10].
For a posteriori methods like PCA, key analytical decisions include selecting the number of patterns to retain (based on eigenvalues >1, scree plots, or interpretability), rotating factors to enhance interpretability (using orthogonal or oblique rotation), and labeling patterns based on foods with high factor loadings [7]. For a priori methods, protocols involve defining dietary components for inclusion, establishing cut-points for scoring each component, and determining weighting and summation methods [6].
Validation and Reprodubility Assessment
Establishing the validity and reproducibility of derived dietary patterns is essential for robust research. Short-term stability can be assessed through test-retest studies, with evidence demonstrating that both a priori scores like the MedDietScore and a posteriori patterns derived from PCA show good stability over 15-day intervals [10]. Reproducibility over longer periods examines whether similar patterns emerge from different dietary assessments within the same population [10]. Validity is typically established by demonstrating expected associations with biomarkers (e.g., blood nutrient levels, inflammatory markers) or health outcomes [5] [11]. For instance, the Dietary Inflammatory Index was specifically developed based on associations with inflammatory biomarkers like C-reactive protein [11].
Applications in Research and Drug Development
Elucidating Diet-Disease Relationships
Dietary pattern analysis has proven particularly valuable in understanding complex relationships between overall diet and chronic disease risk. Strong evidence from systematic reviews and meta-analyses indicates that dietary patterns characterized by higher consumption of vegetables, fruits, whole grains, fish, low-fat dairy, and legumes, and lower consumption of red and processed meats, sugar-sweetened beverages, and refined grains are associated with reduced risk of cardiovascular disease, type 2 diabetes, obesity, certain cancers, and premature mortality [8]. For example, the 2020 Dietary Guidelines Advisory Committee concluded that strong and consistent evidence links such dietary patterns with decreased CVD risk [8].
Different methodological approaches may yield complementary insights. In a study comparing PCA and RRR for diabetes prediction in China, PCA identified a "modern high-wheat" pattern positively associated with diabetes and a "traditional southern" pattern inversely associated, though associations attenuated after adjustment. In contrast, the RRR-derived pattern (combining elements of both PCA patterns) remained significantly associated with diabetes after adjustment, potentially demonstrating superior predictive power for specific outcomes [11].
Informing Clinical Trials and Therapeutic Development
For drug development professionals and clinical researchers, dietary pattern analysis offers several important applications. First, understanding population dietary patterns can help stratify research participants based on background diet, which may interact with pharmacological interventions. Second, dietary patterns can serve as important confounding variables that need adjustment in clinical trials evaluating drug efficacy. Third, dietary interventions themselves represent therapeutic approaches for chronic disease prevention and management, with patterns like the Mediterranean diet and DASH diet demonstrating efficacy comparable to pharmaceutical interventions for certain conditions [5] [11].
Table 2: Key Dietary Patterns and Their Documented Health Associations
| Dietary Pattern | Characteristics | Health Associations |
|---|---|---|
| Mediterranean Diet | High fruits, vegetables, whole grains, legumes, nuts, olive oil; moderate fish/poultry; low red meat [5] | Reduced cardiovascular disease, diabetes, cognitive decline, all-cause mortality [5] [8] |
| DASH Diet | Emphasis on fruits, vegetables, whole grains, low-fat dairy; limited saturated fat, sugar, sodium [5] | Reduced hypertension, cardiovascular disease, stroke [5] [8] |
| Prudent/Healthy Pattern (a posteriori) | High vegetables, fruits, whole grains, fish, poultry [5] | Reduced chronic disease risk, all-cause mortality [8] |
| Western Pattern (a posteriori) | High red/processed meat, refined grains, potatoes, high-fat dairy, sweets [5] | Increased obesity, cardiovascular disease, diabetes, certain cancers [8] |
| Healthy Nordic Diet | Similar to Mediterranean but with rapeseed oil instead of olive oil; emphasis on Nordic foods [8] | Reduced cardiovascular risk, improved metabolic health [8] |
| MIND Diet | Hybrid of Mediterranean and DASH with emphasis on neuroprotective foods [5] | Reduced cognitive decline, neurodegenerative disease [5] |
Implementing robust dietary pattern analysis requires specific methodological tools and approaches. The following table outlines key resources for researchers designing studies in this field.
Table 3: Research Reagent Solutions for Dietary Pattern Analysis
| Tool Category | Specific Examples | Application & Purpose |
|---|---|---|
| Dietary Assessment Instruments | Food Frequency Questionnaires (FFQs), 24-hour recalls, food records [5] | Standardized collection of dietary intake data; FFQs most common for pattern analysis [5] |
| Food Grouping Systems | Standardized food grouping schemes, culture-specific groupings [10] | Aggregate individual foods into meaningful categories for pattern analysis [10] |
| Statistical Software Packages | SAS, R, STATA, SPSS, MATLAB [7] | Implement PCA, factor analysis, cluster analysis, RRR, and emerging methods [7] |
| A Priori Scoring Algorithms | Mediterranean Diet Score, Healthy Eating Index, DASH score calculators [5] [7] | Standardized calculation of predefined diet quality scores [5] |
| Emerging Method Packages | Treelet Transform, Gaussian Graphical Models, Data Mining algorithms [12] [7] [9] | Implement novel pattern analysis techniques beyond traditional methods [12] [9] |
| Validation Tools | Biomarker assays (nutrients, inflammatory markers), reproducibility statistics [5] [10] | Establish validity and reliability of derived dietary patterns [5] [10] |
Future Directions and Conceptual Challenges
Despite significant advances, dietary pattern analysis faces several conceptual and methodological challenges. A persistent limitation is the difficulty in identifying specific bioactive components responsible for observed health effects when analyzing entire dietary patterns [6]. Future research should integrate multi-omics approaches (metabolomics, microbiomics, genomics) to elucidate biological pathways through which dietary patterns influence health [5]. Additionally, most current methods assume dietary patterns are relatively static, whereas dynamic models capturing dietary changes over time are needed [9].
Methodologically, there is growing recognition that different analytical approaches should be viewed as complementary rather than competitive [14] [11]. The choice between a priori and a posteriori methods should be guided by the specific research question: a priori methods are ideal for testing hypotheses about adherence to recommended dietary patterns, while a posteriori methods better suit exploratory analyses of actual eating behaviors in populations [14] [6]. Future methodological development should focus on improving standardization of food grouping, pattern labeling, and validation procedures to enhance comparability across studies [10] [11].
For drug development professionals and researchers, understanding the rationale and methodologies of dietary pattern analysis provides crucial context for interpreting the growing literature on diet-health relationships and designing studies that account for the complex, synergistic nature of human dietary intake. As the field continues to evolve, dietary pattern analysis will remain an essential approach for unraveling the complex relationships between nutrition and human health.
Key Characteristics of A Priori Methods (Diet Quality Scores and Indices)
In nutritional epidemiology, a priori dietary pattern analysis refers to an approach that evaluates the healthfulness of a diet based on pre-defined criteria grounded in current nutritional knowledge and evidence-based diet-health relationships [15]. Unlike exploratory, data-driven methods, a priori methods use scoring systems to assess an individual's adherence to conceptually defined dietary patterns considered important for health promotion and disease prevention [15] [10]. These dietary quality indices translate complex dietary intake data into quantifiable measures that reflect alignment with dietary guidelines or ideal dietary patterns, serving as powerful tools for researchers investigating relationships between overall diet and health outcomes [15] [16].
The fundamental premise of a priori methods is their basis in prior nutritional knowledge rather than dietary patterns specific to the study population. This approach allows for comparisons across different populations and studies, as the scoring criteria remain consistent regardless of the population's actual dietary habits [15] [11]. A priori methods are particularly valuable when researchers aim to test specific hypotheses about how adherence to recommended dietary patterns influences health outcomes, making them well-suited for prospective cohort studies and clinical trials where a predefined concept of "diet quality" is central to the research question [16] [17].
Theoretical Foundations and Methodological Framework
Conceptual Basis of A Priori Methods
A priori dietary indices are founded on the principle that overall dietary patterns, rather than individual nutrients or foods, exert synergistic effects on health outcomes [11]. These indices are constructed based on current scientific evidence linking dietary components to chronic disease risk, with the objective of quantifying risk gradients for major diet-related diseases [15]. The theoretical framework typically derives from one of three approaches: dietary guidelines from national or international authorities (e.g., Healthy Eating Index based on U.S. Dietary Guidelines); culturally-specific healthy dietary patterns (e.g., Mediterranean Diet Scores); or evidence-based patterns targeting specific health outcomes (e.g., Dietary Approaches to Stop Hypertension - DASH) [16] [18].
The methodological framework for developing a priori indices follows established guidelines for constructing composite indicators, as outlined in the Organisation for Economic Co-operation and Development (OECD) handbook [15]. This systematic approach includes: (1) defining the theoretical framework considering index purpose and structure; (2) selecting appropriate indicators; (3) establishing normalization methods including scaling procedures and cutoff points; and (4) determining methods for weighting and aggregating index components [15]. This rigorous framework ensures that the resulting diet quality scores are scientifically sound, transparent, and fit for their intended purpose.
Comparison with A Posteriori Approaches
A priori methods differ fundamentally from a posteriori approaches in their underlying philosophy and application. A posteriori methods, such as principal component analysis or factor analysis, are exploratory techniques that derive dietary patterns empirically from available dietary intake data without pre-conceived hypotheses about what constitutes a "healthy" diet [11] [10]. These data-driven approaches identify common underlying consumption patterns within a specific study population, reflecting actual eating behaviors in that population [15] [11].
The table below summarizes the key distinctions between these two methodological approaches:
Table 1: Comparison of A Priori and A Posteriori Dietary Pattern Methods
| Characteristic | A Priori Methods | A Posteriori Methods |
|---|---|---|
| Basis | Pre-defined based on current nutritional knowledge | Derived empirically from study population data |
| Theoretical Framework | Based on established diet-health relationships | Exploratory, without pre-existing theoretical framework |
| Purpose | Assess adherence to "ideal" dietary patterns | Describe existing dietary patterns in a population |
| Transferability | Consistent across populations (if appropriate) | Population-specific, may not be reproducible |
| Validation | Against health outcomes and mortality | Internal consistency within the study population |
| Examples | Healthy Eating Index (HEI), Mediterranean Diet Score | Principal Component Analysis, Factor Analysis, Cluster Analysis |
A critical distinction lies in the interpretation of patterns: a priori methods explicitly define healthy versus unhealthy patterns based on current science, while a posteriori methods identify patterns that may or may not align with health promotion [15] [11]. For instance, a posteriori approaches might identify a "Western dietary pattern" characterized by high intakes of red meat, processed foods, and refined grains, but this pattern emerges from the data rather than being predefined as unhealthy [11]. This fundamental difference dictates their appropriate application in research settings, with a priori methods being preferable for testing hypotheses about adherence to recommended diets, and a posteriori methods being more suitable for exploring dietary behaviors in specific populations [10].
Core Components of A Priori Diet Quality Indices
Index Structure and Component Selection
The construction of a priori diet quality indices involves several methodological decisions that significantly influence their application and interpretation. The selection of components is a critical first step, with most indices including foods or nutrients with established relationships to health outcomes [15] [16]. Common components across multiple indices include fruits, vegetables, whole grains, nuts, legumes, and limits on red/processed meats, sodium, and sugary beverages [16] [17]. However, the specific components vary depending on the index's theoretical foundation—for example, Mediterranean diet scores typically include olive oil and moderate alcohol, while other indices may emphasize different components [15] [17].
The theoretical framework dictates not only which components are included but also how they are structured. Some indices balance "positive" components (foods to encourage) with "negative" components (foods to limit), while others focus exclusively on either approach [15]. The number of components ranges considerably across indices, from as few as 5-6 to more than 20, with implications for the index's sensitivity and practicality [15] [19]. The choice of components also reflects practical considerations about data availability, as more complex indices require detailed dietary assessment methods that may not be feasible in all research settings [15] [18].
Scoring Systems and Valuation Functions
The scoring methodology represents another critical element in a priori index construction. Valuation functions transform intake levels of each component into a score, typically using categorical (e.g., 0-1 binary scoring) or continuous approaches [15]. For component intake recommendations, three main types of valuation functions are employed: (1) step functions with dichotomous scoring based on meeting a threshold; (2) linear functions where scores increase proportionally with intake; and (3) non-linear functions that may incorporate optimal intake ranges with penalties for both insufficient and excessive consumption [15].
Normalization methods standardize scores across components with different measurement units, while cutoff points define thresholds for minimum and maximum scores [15]. These cutoff points may be based on absolute dietary recommendations (e.g., servings per day according to national guidelines) or on population-specific values (e.g., median or quintile distributions within the study sample) [15] [11]. The choice between absolute and relative cutoff points has significant implications for the index's applicability across different populations with varying dietary habits [11].
Weighting and Aggregation Methods
The aggregation of component scores into an overall diet quality index involves decisions about weighting—whether all components contribute equally or some receive greater weight based on their perceived importance for health [15]. Most commonly, indices use equal weighting for simplicity and transparency, though some employ evidence-based weighting schemes that reflect the strength of association between specific dietary components and health outcomes [15] [16].
The aggregation method itself can take various forms, including simple sums, means, or ratio-based approaches [15]. The choice of aggregation method affects the index's statistical properties and interpretation, with different approaches having distinct advantages and limitations. Regardless of the specific method chosen, transparency in the weighting and aggregation process is essential for appropriate interpretation and comparison across studies [15].
Methodological Implementation and Validation
Construction Workflow
The development of a robust a priori diet quality index follows a systematic workflow that incorporates both theoretical and methodological considerations. The diagram below illustrates the key stages in this process:
Research Toolkit for Implementation
Implementing a priori diet quality assessment in research requires specific methodological tools and considerations. The table below outlines key elements in the researcher's toolkit:
Table 2: Research Toolkit for A Priori Diet Quality Assessment
| Toolkit Component | Description | Examples & Applications |
|---|---|---|
| Dietary Assessment Methods | Instruments for collecting dietary intake data | Food Frequency Questionnaires (FFQs), 24-hour recalls, food records [10] [20] |
| Food Composition Databases | Resources for converting foods to nutrients | USDA Food Composition Database, country-specific nutrient databases [20] [18] |
| Index Scoring Algorithms | Computational procedures for calculating scores | Pre-defined formulas for HEI, DASH, Mediterranean diet scores [15] [17] |
| Validation Measures | Methods for assessing index performance | Correlation with biomarkers, prediction of health outcomes, reliability testing [16] [19] |
| Cultural Adaptation Frameworks | Approaches for tailoring indices to specific populations | Modification of food components, adjustment of portion sizes, inclusion of traditional foods [11] [21] |
Validation Approaches and Performance Assessment
Validating a priori diet quality indices involves assessing both their reliability (consistency of measurement) and validity (accuracy in measuring what they intend to measure) [10] [19]. Reliability testing often includes assessment of short-term stability through test-retest methods, with studies demonstrating good stability for indices like the MedDietScore over a 15-day interval [10]. The use of food groups rather than individual food items appears to enhance stability, explaining more variation in dietary intake (43-46% versus 23-25%) [10].
Validity assessment typically involves evaluating the index's ability to predict health outcomes, with successful indices demonstrating significant associations with reduced risk of chronic diseases, mortality, and more favorable health indicators [16] [17] [19]. For example, in a recent large-scale study of healthy aging, higher adherence to various a priori dietary patterns was associated with 45-86% greater odds of healthy aging, with the Alternative Healthy Eating Index showing the strongest association [17]. Validation also includes comparing index scores with objective biomarkers where possible, and assessing construct validity by examining relationships with socioeconomic, behavioral, and anthropometric variables [16] [19].
Current Applications and Research Evidence
Evidence from Recent Studies
Contemporary research continues to demonstrate the utility of a priori diet quality indices in predicting diverse health outcomes across population groups. A 2025 large-scale study examining eight dietary patterns in relation to healthy aging found that all patterns showed significant associations, with odds ratios for the highest versus lowest quintiles ranging from 1.45 for a healthful plant-based diet to 1.86 for the Alternative Healthy Eating Index [17]. This study defined healthy aging multidimensionally, encompassing freedom from major chronic diseases, intact cognitive and physical function, and good mental health at age 70 years or older [17].
Research in specific population subgroups includes studies in children and adolescents, where diet quality indices have shown associations with improved IQ, quality of life, blood pressure, body composition, and metabolic syndrome prevalence [19]. However, a systematic review noted that only a minority of pediatric indices have been adequately evaluated for validity and reliability, highlighting an important methodological consideration [19]. The application of these indices across diverse cultural contexts also requires careful consideration of local dietary patterns and food availability [11] [21].
Specific Index Performance
Different a priori indices demonstrate varying strengths in predicting specific health outcomes, reflecting their distinctive theoretical foundations and component emphasis:
Table 3: Performance of Selected A Priori Indices in Recent Research
| Diet Quality Index | Key Components | Associated Health Outcomes | Strength of Evidence |
|---|---|---|---|
| Alternative Healthy Eating Index (AHEI) | Fruits, vegetables, whole grains, nuts, legumes, long-chain fats, red/processed meat limitation | Strongest association with healthy aging (OR: 1.86); physical and mental health [17] | Multiple large prospective cohorts |
| Mediterranean Diet Scores | Fruits, vegetables, legumes, cereals, fish, olive oil, moderate alcohol | Reduced cardiovascular risk, diabetes incidence, association with healthy aging [11] [17] | Extensive observational and trial evidence |
| DASH Diet Score | Fruits, vegetables, low-fat dairy, whole grains, sodium limitation | Blood pressure reduction, cardiovascular risk reduction, hypertension prevention [16] [20] | Clinical trials and prospective studies |
| Healthful Plant-Based Diet Index (hPDI) | Plant foods with positive scoring for whole grains, fruits, vegetables, nuts | Modest association with healthy aging (OR: 1.45), weaker than other indices [17] | Emerging evidence from cohort studies |
| Dietary Inflammatory Index (DII) | Multiple pro- and anti-inflammatory food components | Inflammatory biomarkers, chronic disease risk [11] [16] | Mixed evidence across populations |
Methodological Considerations and Limitations
Challenges in Application Across Populations
A significant challenge in applying a priori diet quality indices across different populations relates to cultural and dietary heterogeneity [11] [21]. Indices developed for specific populations may not perform optimally in different settings due to varying dietary patterns and food availability [11]. For example, the Alternative Healthy Eating Index component for trans-fatty acid intake showed limited variability in an Australian population where trans-fat intakes are generally low, reducing its discriminative power [11]. Similarly, attempts to apply the Mediterranean Diet Score in non-Mediterranean populations may be constrained by the fact that even the highest-scoring individuals may not achieve intake levels comparable to traditional Mediterranean diets [11].
The cultural appropriateness of dietary indices is increasingly recognized as essential for their validity and applicability. Research with African American adults has highlighted the importance of adapting dietary guidance to ensure cultural relevance, including consideration of traditional foods and preparation methods [21]. This suggests that rigid application of standardized indices without cultural modification may limit their utility in diverse populations, pointing to the need for careful adaptation while maintaining the core health principles underlying the indices [21] [18].
Technical and Methodological Limitations
Several technical limitations affect the implementation and interpretation of a priori diet quality indices. Component selection involves inherent subjectivity, as researchers must decide which dietary aspects to include and how to define optimal intake levels amid sometimes inconsistent evidence [15] [16]. The weighting of components presents another challenge, with most indices using equal weighting for simplicity despite potential differences in the strength of association between various dietary components and health outcomes [15] [16].
Additional limitations include the lack of standardized cutoff values across indices, varying approaches to handling energy adjustment, and differences in whether indices emphasize increasing healthy foods, limiting unhealthy foods, or both [16]. The validation of scores with biomarkers or other objective assessment methods remains inconsistent, complicating decisions about the most appropriate indices for specific research contexts [16] [19]. Furthermore, many indices do not adequately address issues of dietary substitution—the conceptualization of what replaces what when certain foods are reduced—which may limit their utility for providing specific dietary guidance [16].
Future Directions and Innovations
The evolution of a priori diet quality indices continues with several emerging trends shaping their development. Integration of sustainability concerns represents a frontier in dietary pattern assessment, with newer indices such as the Planetary Health Diet Index incorporating environmental impact alongside health considerations [17] [18]. This reflects growing recognition that dietary guidance must address both human health and planetary boundaries [18].
Methodological innovations include the development of biomarker-based validation of indices to strengthen their objective basis, and efforts to create standardized scoring systems that maintain consistency while allowing for cultural adaptation [11] [16]. The 2014 proposal by Sofi et al. for a literature-based tool standardizing Mediterranean diet adherence scoring across populations exemplifies this direction [11]. Additionally, there is increasing attention to life-course approaches with age-specific indices, particularly for pediatric and older adult populations [19] [18].
As nutritional science evolves, future a priori indices will likely incorporate more nuanced understanding of diet-disease relationships, potentially including interactions with genetics, gut microbiota, and other individual factors [16]. The ongoing refinement of these indices will continue to enhance their utility for researchers, clinicians, and policymakers seeking to understand and promote dietary patterns that support optimal health throughout the lifespan.
Key Characteristics of A Posteriori Methods (Statistical Derivation)
Conceptual Foundation and Definition
A posteriori methods, often termed data-driven or exploratory methods, are a class of statistical techniques used to identify underlying structures or patterns directly from observed data without pre-specified theoretical frameworks. In the context of nutritional epidemiology, these methods derive dietary patterns based on the actual dietary intake data reported by a study population. The primary goal is to summarize a set of food consumption variables into a fewer number of patterns by leveraging the inter-correlations and co-variation among the foods consumed [11] [10] [20]. Unlike a priori approaches, which assess adherence to a pre-defined "ideal" diet, a posteriori methods aim to discover a population's "true" or habitual dietary habits, which may not be easily identifiable as simply "healthy" or "unhealthy" [11] [10]. These methods are considered completely exploratory, as they allow the data itself to reveal the predominant combinations of foods that characterize a population's diet [20].
The core principle behind a posteriori methods is the use of multivariate statistics to reduce data dimensionality. Given that individuals consume a wide variety of foods and nutrients that exhibit complex interactions and synergies, analysing single food items or nutrients in isolation can be limiting and prone to confounding [11] [20]. A posteriori methods address this complexity by identifying latent variables—the dietary patterns—that explain as much of the variation in food intake as possible. The patterns identified reflect the collective dietary behaviors within the study sample, capturing the reality that people eat meals consisting of multiple food items in combination, rather than consuming nutrients in isolation [11]. The resulting patterns are often given descriptive names based on the food items that load highly on them, such as "Western," "Traditional," "Prudent," or "Balanced" [11] [22].
Methodological Workflow
The application of a posteriori methods follows a structured, iterative process from data preparation through to pattern interpretation and validation. The workflow can be visualized as a sequence of key stages, each with distinct objectives and outputs.
Data Preparation and Aggregation
The initial and often most critical phase involves processing raw dietary data into a format suitable for pattern extraction. Dietary data is typically collected using instruments such as Food Frequency Questionnaires (FFQs) or 24-hour dietary recalls, which record the consumption of numerous individual food items [10] [20]. A key decision at this stage is whether to use food items or aggregated food groups as the input variables. Using finely detailed food items can capture subtle dietary habits but may introduce noise and make pattern interpretation challenging. Conversely, aggregating individual foods into logically defined food groups (e.g., "whole grains," "red meat," "dairy") reduces the number of variables, minimizes within-person variation, and often leads to more stable and interpretable patterns that explain a greater proportion of the variance in dietary intake [10]. For instance, one study found that using 12 food groups explained 43-46% of the variance in intake, whereas using 50 individual food items explained only 23-25% of the variance [10].
Statistical Derivation and Interpretation
The core analytical phase employs multivariate techniques to identify patterns. The most common method is Principal Component Analysis (PCA), which uses an orthogonal transformation to convert a set of possibly correlated food variables into a set of linearly uncorrelated variables called principal components [11] [20]. These components are derived in order of their ability to explain the variance in the data. Another technique is Factor Analysis, which is similar to PCA but aims to describe the covariance structure by identifying underlying latent factors that cause the observed variables to co-vary [11]. Cluster Analysis is a related a posteriori method that groups individuals, rather than variables, into distinct clusters based on the similarity of their overall diets [11]. The choice of the number of patterns to retain is guided by statistical criteria (e.g., eigenvalues >1, scree plot) and interpretability [11].
The interpretation of the derived patterns is based on examining the factor loadings, which are correlation coefficients between the original food variables and the derived pattern. Food items or groups with high absolute loadings (positive or negative) contribute most to that pattern and are used to label and define it [11]. For example, a pattern with high positive loadings for fast food, processed meat, and refined grains might be labeled a "Western" pattern, whereas a pattern with high loadings for fruits, vegetables, and whole grains might be labeled "Healthy" or "Prudent" [11] [22]. It is crucial to note that the same pattern name (e.g., "Traditional") can represent vastly different food combinations in different cultural contexts, necessitating careful examination of the actual foods consumed [11].
Comparative Analysis of Statistical Techniques
A posteriori dietary pattern analysis employs several distinct statistical approaches, each with unique objectives, algorithms, and outputs. The selection of a specific technique directly influences how patterns are defined and how individuals are classified.
Table 1: Key Statistical Techniques for A Posteriori Dietary Pattern Derivation
| Technique | Primary Objective | Methodological Approach | Nature of Output | Key Advantages | Key Limitations |
|---|---|---|---|---|---|
| Principal Component Analysis (PCA) [11] [20] | To reduce data dimensionality by creating new, uncorrelated variables that explain maximum variance. | Orthogonal transformation of original variables into principal components. | Continuous pattern scores for each individual for each derived component. | Maximizes explained variance; provides a quantitative score for association studies. | Patterns can be difficult to interpret as all variables have some loading on every component. |
| Factor Analysis [11] | To describe the underlying covariance structure by identifying latent factors. | Models covariance based on shared underlying latent constructs. | Continuous factor scores for each individual. | Can model measurement error; theoretically models causal latent traits. | More complex model assumptions; results can be similar to PCA. |
| Cluster Analysis [11] | To group individuals into distinct categories based on dietary similarity. | Partitions individuals into clusters to minimize within-cluster and maximize between-cluster distance. | Categorical variable assigning each individual to a single cluster. | Creates intuitive, mutually exclusive dietary typologies. | Loss of information by categorizing; sensitivity to choice of algorithm and distance metric. |
| Reduced Rank Regression (RRR) [11] | To derive patterns that maximally explain the variation in specific response variables (e.g., biomarkers). | Supervised method that finds linear combinations of predictors that explain response variation. | Continuous pattern scores. | Potentially stronger predictive power for specific health outcomes by incorporating biological pathways. | Patterns may not represent common eating habits in the population. |
| Treelet Transform (TT) [11] | To combine features of PCA and cluster analysis for dimension reduction with localized variable grouping. | Produces a cluster tree that allows visual examination of how variables group, yielding sparse factors. | Continuous factor scores involving a smaller number of naturally grouped variables. | Easier interpretation of factors as they involve fewer variables; visual output. | Requires subjective selection of the cut-level on the cluster tree. |
Advanced and Hybrid Techniques
Beyond the classical methods, advanced techniques like Reduced Rank Regression (RRR) and Treelet Transform (TT) offer unique advantages. RRR is a supervised method because it derives dietary patterns not only based on food consumption data but also by maximizing their predictive power for pre-specified intermediate biomarkers or disease outcomes (e.g., glycated hemoglobin, inflammatory markers) [11]. This can result in patterns that are more strongly associated with the disease under investigation, as they are constrained by biological pathways. For example, one study found that an RRR-derived pattern was significantly associated with diabetes even after adjustment for confounders, whereas PCA-derived patterns were not [11]. In contrast, Treelet Transform is an unsupervised method that merges the benefits of PCA and cluster analysis. It produces a cluster tree, providing a visual representation of how food variables group together, and yields factors that are easier to interpret than PCA factors because each factor involves a smaller, naturally grouped set of variables [11].
Experimental Protocols and Validation
Standard Protocol for Principal Component Analysis
The most widely used method for deriving a posteriori dietary patterns is Principal Component Analysis. The following provides a detailed, step-by-step protocol based on established research practices [11] [10] [20].
- Dietary Data Collection and Preprocessing: Collect dietary intake data using a validated dietary assessment tool, such as a semi-quantitative Food Frequency Questionnaire (FFQ). The frequency of consumption for each food item is converted to daily intake in grams. Energy adjustment is typically performed using the residual method or by calculating the density of food intake (servings per 1000 kcal).
- Food Grouping: Collapse individual food items from the FFQ into logically defined, mutually exclusive food groups based on similarity of nutrient profile and culinary use (e.g., "whole grains," "refined grains," "red meat," "leafy green vegetables"). This step reduces the number of variables and minimizes random variation.
- Factorability Assessment: Check the suitability of the data for PCA. This is often done using the Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy (values >0.6 are acceptable) and Bartlett's test of sphericity (a significant p-value indicates that correlations between variables are sufficiently large for PCA).
- Component Extraction: Perform PCA on the correlation matrix of the food groups. The number of components to retain is determined by a combination of:
- The Kaiser criterion (eigenvalues >1).
- The scree plot, a graphical representation of eigenvalues where the point of inflection is identified.
- The interpretability of the components, ensuring they explain a meaningful cumulative proportion of variance (often >20%).
- Rotation: Apply an orthogonal rotation (most commonly Varimax) to the retained components. Rotation simplifies the factor structure, maximizing high loadings and minimizing low ones for each component, which aids in interpretation.
- Interpretation and Labeling: Interpret the rotated components by examining the factor loadings. Food groups with high absolute loadings (e.g., > |0.2| or > |0.3|) are considered to contribute significantly to a pattern. Each pattern is labeled based on the foods that load highly on it (e.g., a pattern with high loadings for fast food, processed meat, and fries is labeled "Western").
- Calculation of Pattern Scores: For each participant and each retained pattern, calculate a dietary pattern score. This is typically done by summing the intake of each food group weighted by its factor loading. These scores are standardized and used in subsequent analyses to test associations with health outcomes.
Protocol for Assessing Pattern Stability
A critical step in validating a posteriori patterns is testing their stability and reliability over time. The following protocol, adapted from Bountziouka et al., assesses short-term reliability [10].
- Study Design: A sample of participants (e.g., n=500) completes the same dietary assessment tool (e.g., a 76-item FFQ) twice within a short, predefined interval (e.g., 15 days) to minimize true changes in diet.
- Pattern Derivation per Administration: Apply the same PCA protocol (as described in Section 4.1) independently to the dietary data from the first and second administrations.
- Comparative Analysis:
- Compare the patterns derived from the two time points based on the similarity of the factor loadings for the key food groups.
- Compare the variance explained by the patterns from each administration.
- Assess the stability of individual classification by calculating the correlation (e.g., Kendall's tau-b) between the pattern scores from the two administrations.
- Sensitivity Analysis with Food Groups: Repeat the PCA and stability analysis using aggregated food groups instead of individual food items. Research indicates that using food groups typically results in patterns that explain a higher percentage of variance and demonstrate stronger stability metrics [10].
Successfully implementing a posteriori dietary pattern analysis requires a combination of specific data resources, statistical tools, and methodological components.
Table 2: Essential Research Reagents and Resources for A Posteriori Analysis
| Tool / Resource | Function / Description | Application in Research |
|---|---|---|
| Food Frequency Questionnaire (FFQ) [10] [20] | A validated, semi-quantitative questionnaire assessing habitual intake of a comprehensive list of foods and beverages over a specified period. | The primary instrument for collecting dietary intake data, which serves as the raw material for pattern derivation. |
| Food Composition Table (FCT) [20] | A database detailing the nutrient content of foods. Used to calculate nutrient intakes and aid in food grouping. | Essential for energy adjustment and for creating meaningful, nutritionally coherent food groups for analysis. |
| Statistical Software (e.g., R, SAS, SPSS, Stata) | Software platforms with robust multivariate statistical procedures. | Used to perform the core analyses: Principal Component Analysis, Factor Analysis, Cluster Analysis, and Reduced Rank Regression. |
| Varimax Rotation [11] | An orthogonal rotation method used in factor analysis to simplify the structure of the factor loadings matrix. | Applied after factor extraction to achieve a simpler, more interpretable structure where each variable loads highly on as few factors as possible. |
| Food Grouping Schema [10] | A pre-defined system for aggregating individual food items from an FFQ into broader, meaningful categories. | Reduces data dimensionality and noise, leading to more stable and interpretable dietary patterns. |
| Stability Metrics (e.g., Kendall's tau-b) [10] | Statistical measures of rank correlation used to assess the test-retest reliability of derived pattern scores. | Quantifies the short-term stability of the dietary patterns and the consistency of individual classification. |
Analytical Pathways and Research Outcomes
The ultimate goal of deriving a posteriori dietary patterns is to link them to health outcomes, a process that involves multiple analytical steps and decision points. The following diagram maps the logical pathway from raw data to public health insight.
This analytical pathway yields critical insights. For instance, a recent meta-analysis found that a posteriori-derived "Western dietary pattern" was associated with a 54% increased risk of Parkinson's Disease (RR=1.54), while a "Healthy dietary pattern" was associated with a 24% reduced risk (RR=0.76) [22]. However, not all analyses find significant associations, as seen in a prospective study where neither a healthy nor an unhealthy a posteriori pattern was associated with the risk of hypertension, highlighting the context-dependent nature of these findings [20]. The robustness of these conclusions hinges on the careful execution of each step in the methodological workflow, from data collection through to statistical derivation and validation.
Comparative Strengths and Limitations of Each Foundational Approach
Dietary pattern analysis has emerged as a fundamental methodology in nutritional epidemiology, shifting the focus from individual nutrients to the complex combinations of foods that constitute whole diets [7]. This shift recognizes that humans consume foods with multiple interacting components rather than isolated nutrients, and these interactions create synergistic or antagonistic effects on health outcomes [12]. The two foundational approaches for analyzing dietary patterns are classified as a priori (investigator-driven) and a posteriori (data-driven) methods, each with distinct philosophical underpinnings, methodological frameworks, and applications in research settings [7] [12].
A priori methods are defined by investigator-driven hypotheses based on existing nutritional knowledge, dietary guidelines, or scientific evidence about diet-disease relationships [7] [23]. These approaches operationalize predefined dietary concepts into quantitative scores that measure adherence to recommended eating patterns. In contrast, a posteriori methods are empirically derived from population dietary data without predetermined nutritional hypotheses [12] [23]. These data-driven approaches use statistical techniques to identify existing eating patterns within study populations, allowing unique dietary cultures and habits to emerge from the data itself [24].
The comparative analysis of these foundational approaches provides researchers with critical insights for selecting appropriate methodological frameworks based on specific research questions, study populations, and analytical resources. This technical guide examines the strengths, limitations, and applications of each approach within the broader context of nutritional epidemiology and dietary pattern research.
Methodological Foundations
A Priori (Investigator-Driven) Approaches
Core Principles and Development
A priori methods are grounded in nutritional science evidence and dietary recommendations, translating existing knowledge into structured scoring systems [7]. The fundamental principle underlying these approaches is that dietary guidelines based on extensive research can be operationalized to evaluate how closely individuals' diets align with patterns associated with health outcomes [7]. Researchers develop these scoring systems by selecting food components, defining intake thresholds, and assigning points based on adherence to recommendations, creating a composite score that represents overall diet quality [7].
The development process involves several systematic stages: First, researchers identify relevant dietary components based on current scientific evidence and dietary guidelines. Second, they establish scoring criteria for each component, typically defining optimal intake ranges. Third, they determine weighting schemes that may assign equal or differential importance to various components. Finally, they validate the scores against health outcomes to ensure they predict relevant disease endpoints [7]. This rigorous development process ensures that a priori scores reflect current scientific understanding of diet-disease relationships while maintaining practical applicability in research settings.
Common A Priori Indices and Their Components
Several well-established a priori indices are widely used in nutritional epidemiology, each with distinct compositional frameworks:
Alternative Healthy Eating Index (AHEI): Developed as an enhancement to the original Healthy Eating Index, the AHEI showed the strongest association with healthy aging in a recent large prospective study, with an odds ratio of 1.86 (95% CI: 1.71-2.01) comparing the highest to lowest quintiles [17]. The index emphasizes fruits, vegetables, whole grains, nuts, legumes, long-chain fats, and polyunsaturated fatty acids while discouraging red and processed meats, sugar-sweetened beverages, trans fats, and sodium [17].
Alternative Mediterranean Diet Score (aMED): This index operationalizes the traditional Mediterranean diet pattern, characterized by high consumption of fruits, vegetables, nuts, legumes, whole grains, and extra-virgin olive oil; moderate consumption of poultry, fish, and alcohol; and low consumption of red and processed meats [4] [17]. A recent meta-analysis demonstrated that adherence to the Mediterranean diet was associated with an 13% decreased risk of Parkinson's disease (RR = 0.87; 95% CI: 0.78-0.97) [4].
Dietary Approaches to Stop Hypertension (DASH): This pattern emphasizes nutrients associated with blood pressure regulation, including high intake of fruits, vegetables, whole grains, low-fat dairy, and limited red meat, saturated fats, and sweets [7] [17].
Dietary Inflammatory Index (DII): This index quantifies the inflammatory potential of diet based on scientific evidence linking dietary components to inflammatory biomarkers [23]. In a prospective cohort study of 189,561 participants, higher DII scores were associated with a 17% increased risk of lung cancer (HR T3 vs. T1: 1.17; 95% CI: 1.00, 1.36) [23].
Healthful Plant-Based Diet Index (hPDI): This index assesses adherence to a plant-based diet that emphasizes healthy plant foods while still accounting for the quality of plant-based components [17]. In healthy aging research, hPDI demonstrated the weakest association among the dietary patterns examined (OR = 1.45; 95% CI: 1.35-1.57) [17].
Table 1: Major A Priori Dietary Indices and Their Components
| Index Name | Key Components | Scoring Range | Primary Health Outcomes |
|---|---|---|---|
| Alternative Healthy Eating Index (AHEI) | Fruits, vegetables, whole grains, nuts, legumes, unsaturated fats | 0-110 | Healthy aging (OR=1.86), chronic disease prevention [17] |
| Alternative Mediterranean Diet (aMED) | Fruits, vegetables, whole grains, legumes, nuts, olive oil, fish | 0-9 | Neurodegenerative disease risk reduction (RR=0.87) [4] [17] |
| DASH Diet | Fruits, vegetables, whole grains, low-fat dairy, limited red meat | 0-10 | Blood pressure control, cardiovascular health [7] |
| Dietary Inflammatory Index (DII) | Pro- and anti-inflammatory food components | Varies | Lung cancer risk (HR=1.17), inflammatory diseases [23] |
| Healthful Plant-Based Diet Index (hPDI) | Whole grains, fruits, vegetables, nuts, legumes, teas & coffee | 0-90 | Healthy aging (OR=1.45), metabolic health [17] |
A Posteriori (Data-Driven) Approaches
Statistical Foundations and Techniques
A posteriori methods utilize statistical dimensionality reduction techniques to identify eating patterns that naturally exist within population dietary data [7] [12]. These approaches are founded on the principle that dietary behaviors exhibit covariance structures that can be captured through multivariate statistical methods, allowing researchers to identify common combinations of foods that people actually consume without predefined nutritional hypotheses [7].
The most commonly applied a posteriori techniques include:
Principal Component Analysis (PCA) and Factor Analysis (FA): These related techniques identify patterns of food consumption by analyzing the correlation matrix between food groups [7] [23]. PCA creates new uncorrelated variables (principal components) that explain maximum variance in food consumption, while FA identifies latent constructs (factors) that explain the covariation among food groups [7]. In practice, researchers pre-group individual food items into food groups, calculate correlation matrices, extract components or factors based on eigenvalues (>1.0 typically), rotate solutions (often varimax) for interpretability, and name patterns based on factor loadings (typically ≥|0.3|) [7] [23] [24].
Cluster Analysis: This technique classifies individuals into mutually exclusive groups based on similarity in their dietary intake patterns [7] [12]. Unlike PCA/FAs, which identify patterns of intercorrelated foods, cluster analysis identifies groups of people with similar dietary behaviors, creating taxonomies of dietary patterns within populations [12].
Emerging Methods: Recent methodological advances include machine learning algorithms, latent class analysis, treelet transform, and compositional data analysis, which offer enhanced capabilities for capturing complex dietary synergies and patterns [7] [12].
Commonly Identified A Posteriori Patterns
Across diverse populations, a posteriori analyses consistently identify several archetypal dietary patterns:
Healthy/Prudent Patterns: Characterized by high consumption of fruits, vegetables, legumes, whole grains, poultry, and fish [4] [23] [24]. In a prospective cohort study, this pattern was specifically labeled "Balanced and nutritious pattern" and was associated with significantly better overall survival in epithelial ovarian cancer patients (HR = 0.40, 95% CI = 0.17-0.95) [24]. Similarly, a "fruits and vegetables dietary pattern" identified through factor analysis was associated with a 22% lower risk of lung cancer (HR T3 vs. T1: 0.78; 95% CI: 0.67, 0.91) [23].
Western/Energy-Dense Patterns: Characterized by high consumption of red and/or processed meat, refined grains, French fries, sweets, desserts, and high-fat dairy products, and low consumption of fruits and vegetables [4] [24]. A meta-analysis of Parkinson's disease risk found high adherence to this pattern was associated with a 54% increased risk (RR = 1.54; 95% CI: 1.10-2.15) [4]. In ovarian cancer research, this pattern was associated with decreased overall survival when patients changed from low to high adherence after diagnosis [24].
Traditional Patterns: These patterns are population-specific and reflect cultural or regional eating habits. For example, in a Scottish cohort study, a "traditional" pattern reflected local dietary customs and was associated with poorer cognitive performance after adjustment for childhood intelligence (ηp² = 0.035 for verbal ability) [25].
Table 2: Common A Posteriori Dietary Patterns and Health Associations
| Pattern Name | Characteristic Foods | Variance Explained | Health Associations |
|---|---|---|---|
| Healthy/Prudent Pattern | Fruits, vegetables, legumes, whole grains, poultry, fish | Typically 5-10% per factor | Reduced PD risk (RR=0.76), better ovarian cancer survival (HR=0.40) [4] [24] |
| Western Pattern | Red/processed meats, refined grains, sweets, high-fat dairy | Typically 5-10% per factor | Increased PD risk (RR=1.54), worse metabolic outcomes [4] |
| Traditional Pattern | Population-specific traditional foods | Varies by population | Mixed associations; in Scottish cohort linked to poorer cognitive performance [25] |
| Meat Dietary Pattern | Meat and meat products | 28.54% total variance across 3 patterns | Increased lung cancer risk (HR=1.18, 95% CI: 1.02, 1.37) [23] |
Comparative Analysis of Strengths and Limitations
Methodological and Conceptual Comparisons
The fundamental distinction between a priori and a posteriori approaches lies in their conceptual orientation: a priori methods are hypothesis-driven based on existing knowledge, while a posteriori methods are exploratory and hypothesis-generating based on empirical data [7] [12]. This core difference manifests in several methodological characteristics that influence their application in research settings.
A priori scores offer the advantage of predefined criteria that enable direct comparisons across studies and populations [7]. For example, the Mediterranean diet score can be applied consistently across different cultural contexts to examine adherence to this specific dietary pattern [4]. However, this standardization comes at the cost of flexibility, as a priori scores may not capture unique dietary cultures or emerging patterns not incorporated into the scoring criteria [12]. Additionally, the subjective decisions involved in selecting components, thresholds, and weighting schemes introduce investigator bias into a priori methods [7].
A posteriori methods excel at identifying population-specific dietary patterns that reflect actual eating behaviors without preconceived nutritional hypotheses [12] [24]. This allows unique dietary cultures to emerge from the data, providing insights into local food combinations that might not be captured by standardized indices [24]. However, the patterns identified are highly dependent on the specific study population, dietary assessment methods, and statistical decisions made during analysis, limiting comparability across studies [7] [12]. Furthermore, the labeling and interpretation of derived patterns remain subjective, despite the data-driven origin of the patterns themselves [7].
Practical Applications in Research
The choice between a priori and a posteriori approaches should be guided by research objectives, study population characteristics, and methodological considerations [7]. A priori methods are particularly suitable for studies evaluating adherence to specific dietary recommendations, comparing diet quality across populations or time periods, or examining diet-disease relationships with strong prior hypotheses based on existing evidence [7] [17]. For example, research on the Mediterranean diet's association with Parkinson's disease risk appropriately utilized a priori scoring to test this specific hypothesis [4].
A posteriori methods are ideal for exploratory research in populations with unique dietary cultures, investigations of dietary transitions, or studies aiming to identify novel diet-disease relationships without strong prior hypotheses [12] [23]. For instance, research examining dietary patterns in relation to lung cancer risk utilized factor analysis to identify a "fruits and vegetables pattern" and "meat pattern" specific to the study population [23]. The ovarian cancer survival study employed principal component analysis to derive patterns relevant to the patient population rather than imposing predefined dietary frameworks [24].
Increasingly, researchers employ both approaches complementarily to leverage their respective strengths [23]. The lung cancer study combined both methods, using a priori DII alongside a posteriori patterns to provide a more comprehensive understanding of dietary influences on disease risk [23]. This integrated approach allows researchers to test specific hypotheses while remaining open to discovering unexpected relationships.
Experimental Protocols and Methodological Workflows
Standardized Protocol for A Priori Analysis
Dietary Assessment and Data Preparation
The implementation of a priori dietary pattern analysis follows a systematic protocol beginning with dietary assessment. Validated food frequency questionnaires (FFQs), 24-hour recalls, or food records collect detailed information on food consumption [23] [24]. The dietary data undergoes rigorous cleaning and processing:
Food Grouping: Individual food items are aggregated into predefined food groups based on nutritional similarity and culinary use [24]. For example, in the ovarian cancer study, 111 food items were reclassified into 19 predefined food groups [24].
Nutrient Calculation: Food composition tables translate food consumption into nutrient intakes. In the Chinese ovarian cancer study, researchers used the Chinese Food Composition Table for this purpose [24].
Energy Adjustment: Nutrient intakes are typically adjusted for total energy intake using regression residuals or density methods to isolate pattern effects from total consumption effects [17].
Score Calculation: Component scores are calculated based on adherence to predefined thresholds, then summed into total scores. For example, the AHEI assigns scores for 11 components with a maximum of 110 points [17].
Statistical Analysis Plan
The analytical phase follows a standardized approach:
Categorization: Continuous dietary scores are often categorized into quintiles or tertiles to examine non-linear relationships with health outcomes [17] [23]. For instance, the healthy aging study compared highest versus lowest quintiles of dietary pattern scores [17].
Model Specification: Multivariable regression models (Cox proportional hazards for survival outcomes, logistic regression for binary outcomes, linear regression for continuous outcomes) estimate associations between dietary patterns and health endpoints while controlling for confounding variables [17] [23] [24].
Confounder Adjustment: Models typically adjust for demographic factors (age, sex), socioeconomic status (education, income), lifestyle variables (smoking, physical activity), and energy intake [17] [23]. The healthy aging study adjusted for age, sex, ethnicity, socioeconomic status, marital status, family history of disease, menopausal status and hormone use, medication use, multivitamin use, and multiple lifestyle factors [17].
Sensitivity Analyses: Researchers conduct stratified analyses, examine effect modification, and test different modeling assumptions to assess robustness of findings [17].
Standardized Protocol for A Posteriori Analysis
Dietary Pattern Extraction
The methodological workflow for a posteriori pattern analysis involves specific statistical procedures for pattern extraction:
Food Grouping and Standardization: Individual food items from FFQs or dietary records are grouped into meaningful food groups based on nutritional properties and consumption patterns [23] [24]. In the lung cancer study, 15 food groups were created for factor analysis [23]. Food group intakes are typically standardized (usually as grams per day or percent of total energy) and adjusted for energy intake using regression residuals or density methods [23].
Factorability Assessment: Before pattern extraction, researchers assess the suitability of data for factor analysis using the Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy (values >0.5 acceptable) and Bartlett's test of sphericity (p<0.05 indicates sufficient correlations) [23]. The lung cancer study reported KMO=0.509 and Bartlett's test p<0.001 [23].
Factor Extraction and Retention: Principal component analysis or factor analysis extracts patterns from the correlation matrix between food groups. The number of factors retained follows multiple criteria: eigenvalues >1.0, scree plot inflection point, and interpretability [7] [23] [24]. The ovarian cancer study used eigenvalue >1.0 and scree plot examination, retaining two factors that explained a cumulative variance of 28.54% across 15 food groups [23] [24].
Factor Rotation and Interpretation: Varimax rotation (orthogonal) or promax rotation (oblique) simplifies factor structure for interpretability [7] [24]. Food groups with absolute factor loadings ≥|0.3| are considered meaningful contributors to a pattern [23] [24]. Researchers then label patterns based on the highest-loading food groups, such as "Balanced and nutritious pattern" or "Energy-dense pattern" [24].
Pattern Score Calculation and Validation
After pattern identification, researchers calculate pattern scores for each participant:
Score Calculation: Pattern scores are computed as weighted sums of standardized food group intakes, using factor loadings as weights [7]. Alternatively, simplified methods using sums of key food groups may be employed.
Validation Procedures: Internal validation includes examining pattern stability through split-sample analysis, cross-validation, or bootstrap methods [7] [12]. External validation assesses whether similar patterns emerge in different populations or whether patterns predict relevant health outcomes [7].
Association Analysis: Similar to a priori methods, pattern scores are related to health outcomes using appropriate statistical models with comprehensive confounding adjustment [23] [24].
Core Statistical Software and Packages
Implementation of dietary pattern analysis requires specialized statistical software and packages capable of handling complex multivariate procedures:
Table 3: Essential Software and Packages for Dietary Pattern Analysis
| Software/Package | Primary Functions | Implementation Requirements |
|---|---|---|
| SAS Statistical Software | Comprehensive multivariate analysis, PROC FACTOR, PROC PRINCOMP, PROC CLUSTER | Advanced programming skills, licensed software [7] |
| R Statistical Environment | Multiple specialized packages (psych, FactoMineR, cluster), flexible visualization | Programming proficiency, open-source platform [7] |
| STATA Statistical Package | Factor analysis, cluster analysis, regression modeling | Licensed software, moderate programming requirements [7] |
| SPSS Statistical Software | User-friendly interface for factor analysis, clustering, regression | Licensed software, minimal programming required [7] |
Dietary Assessment and Validation Tools
Accurate dietary pattern analysis depends on robust assessment methodologies:
Food Frequency Questionnaires (FFQs): Semiquantitative instruments assessing habitual intake over extended periods (typically 1 year). The ovarian cancer study used a validated 111-item FFQ with seven frequency categories from "almost never" to "≥2 times per day" [24]. Validation studies should report correlation coefficients (Spearman and intraclass correlation coefficients >0.5 acceptable) and validity coefficients (0.26-0.70 range for main food groups) [24].
24-Hour Dietary Recalls: Detailed interviews capturing previous day's intake, used in large cohorts like UK Biobank [23]. Multiple recalls (2-3 non-consecutive days) improve habitual intake estimation.
Food Composition Databases: Country-specific databases (e.g., Chinese Food Composition Table, USDA Food Composition Database) essential for converting food consumption to nutrient intakes [24].
Dietary Pattern Validation Resources: Split-sample cross-validation protocols, bootstrap resampling methods, and nutrient biomarker correlation studies (e.g., blood carotenoids for fruit/vegetable validation) [7] [12].
The comparative analysis of a priori and a posteriori approaches reveals complementary strengths that can be strategically leveraged in nutritional epidemiology research. A priori methods provide standardized, hypothesis-driven frameworks grounded in existing evidence, enabling direct comparison across studies and populations [7]. Their limitation lies in potential insensitivity to population-specific dietary patterns and cultural variations in eating behaviors [12]. A posteriori methods excel at identifying unique dietary cultures and emerging patterns without predefined hypotheses, but suffer from limited comparability across studies and subjectivity in pattern interpretation [7] [12].
The optimal application of these methodologies depends on specific research objectives. A priori approaches are ideal for testing specific dietary hypotheses, evaluating adherence to guidelines, and conducting cross-population comparisons [4] [17]. A posteriori methods are preferred for exploratory research in unique populations, dietary transition studies, and hypothesis generation [23] [24]. The most comprehensive understanding emerges from integrating both approaches, as demonstrated in studies that combine a priori indices with data-driven patterns to provide complementary insights into diet-disease relationships [23].
Future methodological developments will likely focus on emerging techniques including machine learning algorithms, latent class analysis, treelet transform, and compositional data analysis, which offer enhanced capabilities for capturing dietary complexity [7] [12]. However, regardless of methodological advances, careful consideration of research questions, population characteristics, and methodological tradeoffs will continue to guide appropriate selection between these foundational approaches to dietary pattern analysis.
Methodologies in Action: Applying Dietary Pattern Analysis in Research
In nutritional epidemiology, the analysis of dietary patterns has emerged as a superior approach to understanding the complex relationship between diet and health, moving beyond the limitations of single-food or single-nutrient studies. This holistic methodology primarily operates through two distinct pathways: a priori and a posteriori pattern analysis [11]. A posteriori (data-driven) methods use multivariate statistical techniques like principal component analysis (PCA) to derive dietary patterns directly from consumption data of a specific study population [26]. In contrast, a priori methods evaluate dietary intake against predetermined, hypothesis-oriented patterns that reflect ideal dietary concepts based on scientific evidence and dietary guidelines [11] [10].
The Healthy Eating Index (HEI) and Mediterranean Diet Score (MDS) represent two prominent and scientifically validated a priori approaches that translate dietary guidance into quantifiable metrics [11] [27]. These indices serve as crucial tools for researchers investigating associations between overall diet quality and health outcomes, as they are based on predefined "ideal" dietary patterns rather than being derived from the specific dietary data of the study population [10]. This technical guide provides an in-depth examination of the HEI and MDS, detailing their development, scoring methodologies, validation protocols, and practical applications within the context of comparative dietary pattern research for scientific and drug development professionals.
Theoretical Foundations: A Priori vs. A Posteriori Dietary Pattern Analysis
A priori dietary pattern analysis is fundamentally different from a posteriori methods in both objective and application. While a posteriori methods (e.g., principal component analysis, factor analysis, cluster analysis) identify eating patterns that actually exist within a study population, a priori methods test how well individuals adhere to a predefined dietary pattern that is hypothesized to be beneficial for health [11] [26]. This distinction has significant implications for research design and interpretation.
Comparative Performance: Research directly comparing these approaches has demonstrated that both a priori and a posteriori methods achieve similar predictive accuracy for health outcomes. A landmark case/control study employing multiple classification algorithms (multiple logistic regression, naïve Bayes, decision trees, RIPPER, artificial neural networks, and support vector machines) found equivalent performance for predicting acute coronary syndrome and ischemic stroke, with C-statistics ranging from 0.587-0.807 for a priori and 0.583-0.827 for a posteriori methods [26]. This suggests the choice between methods should be driven by the specific research question rather than presumed superiority of either approach [14] [26].
Methodological Stability: Studies evaluating the short-term stability (repeatability) of dietary patterns have found both a priori and a posteriori methods produce consistent results when administered over a 15-day interval, with a priori patterns demonstrating particularly high stability when based on food groups rather than individual food items [10].
Table 1: Core Characteristics of A Priori and A Posteriori Dietary Pattern Methods
| Characteristic | A Priori Methods (HEI, MDS) | A Posteriori Methods (PCA, Factor Analysis) |
|---|---|---|
| Basis | Pre-defined ideal diet | Existing dietary data in study population |
| Objective | Assess adherence to dietary ideal | Identify prevalent dietary patterns |
| Interpretation | Hypothesis-driven | Data-driven/exploratory |
| Cross-Population Comparability | High (when carefully adapted) | Limited to specific population |
| Primary Output | Score/index value | Patterns/factors with factor loadings |
Figure 1: Conceptual Workflow of A Priori vs. A Posteriori Dietary Pattern Analysis
Development and Evolution
The HEI was originally developed in 1995 by the United States Department of Agriculture (USDA) Center for Nutrition Policy and Promotion in collaboration with the National Cancer Institute (NCI) to evaluate how well American diets conform to the Dietary Guidelines for Americans [28]. The index has undergone several revisions to maintain alignment with updated scientific evidence and dietary recommendations, with the HEI-2020 representing the current version corresponding to the 2020-2025 Dietary Guidelines [28].
The HEI is founded on a density-based scoring approach (amounts per 1000 calories or as a percentage of calories), which allows for comparison of diet quality independent of quantity consumed. This methodological principle enables valid assessments across different demographic groups and caloric requirements [27] [28].
Component Structure and Scoring System
The HEI-2020 comprises 13 components across two broad categories: adequacy components (higher scores indicate higher consumption) and moderation components (higher scores indicate lower consumption) [28]. The total maximum score is 100, representing perfect alignment with dietary recommendations.
Table 2: HEI-2020 Components and Scoring Standards
| Component | Points | Scoring Standard (Ages 2+) |
|---|---|---|
| Adequacy Components | ||
| Total Fruits | 5 | ≥0.8 cup eq./1000 kcal |
| Whole Fruits | 5 | ≥0.4 cup eq./1000 kcal |
| Total Vegetables | 5 | ≥1.1 cup eq./1000 kcal |
| Greens and Beans | 5 | ≥0.2 cup eq./1000 kcal |
| Whole Grains | 10 | ≥1.5 oz eq./1000 kcal |
| Dairy | 10 | ≥1.3 cup eq./1000 kcal |
| Protein Foods | 5 | ≥2.5 oz eq./1000 kcal |
| Seafood and Plant Proteins | 5 | ≥0.8 oz eq./1000 kcal |
| Fatty Acids | 10 | (PUFAs + MUFAs)/SFAs ≥2.5 |
| Moderation Components | ||
| Refined Grains | 10 | ≤1.8 oz eq./1000 kcal |
| Sodium | 10 | ≤1.1 gram/1000 kcal |
| Added Sugars | 10 | ≤6.5% of energy |
| Saturated Fats | 10 | ≤8% of energy |
Scoring Methodology and Calculation
HEI scores are calculated using a multi-step process that transforms dietary intake data into standardized scores. For each component, a density is first calculated (amount per 1000 calories or as a percentage of calories). This density is then compared to predefined standards to determine the score, which can be a proportional value between 0 and the maximum for that component [27] [28].
The scoring system follows these fundamental principles:
- Each component score is independent (one component does not influence another)
- Scores are based on energy-adjusted amounts
- Higher total scores indicate better alignment with Dietary Guidelines
- All components are equally important to the total score
Conceptual Foundation and Variations
The Mediterranean Diet Score (MDS) operationalizes the traditional dietary pattern characteristic of the Mediterranean region, which has been consistently associated with reduced risk of chronic diseases and all-cause mortality [29] [30]. Unlike the HEI, which is based on official dietary guidelines, the MDS captures a culturally-defined dietary pattern that emerged from observational studies of population health.
Several MDS variations exist, with the most widely used being the 14-item Mediterranean Diet Adherence Screener (MEDAS) developed for the PREDIMED study and the original MDS based on median intakes within study populations [11] [29] [30]. A key distinction between MDS approaches is whether they use population-specific median intakes or absolute cut-off values for scoring [11].
Component Structure and Scoring Systems
The Mediterranean diet pattern emphasizes: high consumption of olive oil (particularly extra-virgin), fruits, vegetables, whole grains, legumes, and nuts; moderate consumption of fish, poultry, and wine (with meals); and low consumption of red meat, processed foods, and sweets [29] [31].
Table 3: Mediterranean Diet Score Components and Scoring Criteria
| Component | Traditional MDS Scoring | MEDAS (14-item) Scoring |
|---|---|---|
| Favorable Components | ||
| Vegetables | Above sex-specific median: 1 point | ≥2 servings/day: 1 point |
| Fruits | Above sex-specific median: 1 point | ≥3 servings/day: 1 point |
| Legumes | Above sex-specific median: 1 point | ≥3 servings/week: 1 point |
| Cereals/Whole Grains | Above sex-specific median: 1 point | ≥3 servings/week whole grains: 1 point |
| Fish/Seafood | Above sex-specific median: 1 point | ≥3 servings/week: 1 point |
| Olive Oil | - | Use as principal source of fat: 1 point |
| Nuts | - | ≥3 servings/week: 1 point |
| Unfavorable Components | ||
| Meat/Meat Products | Below sex-specific median: 1 point | <1 serving/day: 1 point |
| Dairy Products | Below sex-specific median: 1 point | - |
| Alcohol | 5-25g/day (men), 5-15g/day (women): 1 point | 1 glass/day (women), 2 glasses/day (men): 1 point |
| Additional MEDAS Items | ||
| - | - | Prefer white meat over red: 1 point |
| - | - | ≥4 tablespoons olive oil/day: 1 point |
| - | - | <1 serving butter/margarine/day: 1 point |
| - | - | <1 serving SSB/day: 1 point |
| - | - | ≥2 servings/week sofrito: 1 point |
| Total Score Range | 0-9 points | 0-14 points |
Scoring Methodology and Calculation
The traditional MDS typically uses sex-specific median values from the study population as cut-offs, with participants receiving 1 point for each component where their consumption is in the beneficial direction relative to the median [11]. In contrast, the MEDAS utilizes absolute intake thresholds based on typical consumption in Mediterranean populations, which enhances cross-population comparability but may reduce sensitivity in non-Mediterranean populations where even high adherence may not reach traditional consumption levels [11] [29].
Experimental Protocols and Validation Studies
HEI Validation and Application Protocol
Validation Methodology: The HEI validation follows a rigorous process assessing content validity, construct validity, and reliability [27]. In one validation study for a Short Healthy Eating Index (sHEI), researchers employed a classification and regression tree (CRT) algorithm with iterative expert feedback to refine the scoring system [27]. The validation utilized concurrent criterion validation, comparing sHEI scores from 50 participants with their HEI scores derived from 24-hour recalls [27].
Key Validation Results:
- Total HEI score from CRT algorithm highly correlated with 24-hour recall HEI score (r = 0.79) [27]
- Individual food group correlations ranged from 0.44 (refined grains) to 0.64 (whole fruits) [27]
- Strong correlations (>0.49) observed for fruits, vegetables, dairy, added sugar, sugar-sweetened beverages, and calcium [27]
Application Workflow:
- Dietary Assessment: Collect dietary intake data via 24-hour recalls, food records, or food frequency questionnaires (FFQs)
- Food Group Classification: Classify consumed foods into HEI component categories
- Density Calculation: Calculate consumption densities per 1000 calories
- Component Scoring: Score each component based on established standards
- Total Score Calculation: Sum component scores for total HEI (0-100)
Figure 2: HEI Scoring and Validation Workflow
MDS Validation and Application Protocol
Multi-National Validation Protocol: A comprehensive validation of the 14-item MEDAS was conducted across seven countries (Greece, Portugal, Italy, Spain, Cyprus, North Macedonia, and Bulgaria) using a standardized protocol [29]. The validation employed a 3-day food diary (3d-FD) as reference method, with participants instructed to record all food and beverages consumed immediately after intake, including cooking methods and amounts in household measures [29].
Test-Retest Reliability Assessment: Participants completed the MEDAS questionnaire twice within a one-week interval to assess reliability. The questionnaires were administered via email link or personal interview [29].
Statistical Validation Metrics:
- Pearson Correlation: Estimated relationship between MEDAS and reference method
- Intraclass Correlation Coefficient (ICC): Assessed agreement between measurements
- Kappa Statistics: Evaluated agreement for individual food items
- Bland-Altman Analysis: Quantified bias and limits of agreement
Key Validation Results:
- Moderate correlation between 14-MEDAS and food diary for entire population (r = 0.573, p < 0.001; ICC = 0.692, p < 0.001) [29]
- Strongest correlation in Mediterranean countries, particularly Greece [29]
- Bland-Altman analysis showed overestimation of MEDAS score in whole population (0.79 ± 1.81) but variable across countries [29]
- ≥50% of food items exhibited fair or better agreement in Greece, Portugal, Italy, and Spain [29]
Comparative Analysis: HEI vs. MDS in Research Applications
Methodological Distinctions and Research Applications
The HEI and MDS, while both a priori methods, serve distinct research purposes and embody different philosophical approaches to defining "healthy" dietary patterns.
Table 4: Comparative Analysis of HEI and MDS Applications
| Characteristic | Healthy Eating Index (HEI) | Mediterranean Diet Score (MDS) |
|---|---|---|
| Basis | Dietary Guidelines for Americans | Traditional Mediterranean eating patterns |
| Primary Application | Evaluate conformity to national guidelines | Test health benefits of Mediterranean diet |
| Scoring Approach | Density-based (per 1000 kcal) | Frequency-based or median-based |
| Cross-Population Comparability | High for similar Western populations | Limited without standardization |
| Component Flexibility | Fixed components | Multiple variations exist |
| Validation Population | US population (NHANES) | Mediterranean populations initially |
| Strengths | Comprehensive; aligns with US policy; detailed component analysis | Strong evidence base for chronic disease prevention; cultural relevance |
| Limitations | US-centric; may not capture all healthful patterns | Limited applicability in non-Mediterranean contexts |
Predictive Validity for Health Outcomes
Both indices have demonstrated significant associations with health outcomes, though the specific outcomes and strength of associations vary:
HEI Health Associations:
- Higher scores associated with reduced risk of cardiovascular disease, type 2 diabetes, and some cancers [27]
- Every 10-point increase in HEI-2015 associated with 7% lower risk of cardiovascular disease (meta-analysis) [27]
- Current average US HEI score: 58/100, indicating substantial room for improvement [28]
MDS Health Associations:
- Umbrella review of meta-analyses (12.8 million subjects) found reduced risk of overall mortality, cardiovascular diseases, cancer, neurodegenerative diseases, and type 2 diabetes [29]
- Systematic review and meta-analysis showed high adherence associated with 13% lower risk of Parkinson's disease (RR = 0.87; 95%CI: 0.78-0.97) [22]
- In PREDIMED study, higher MEDAS scores associated directly with HDL-cholesterol and inversely with BMI, waist circumference, triglycerides, and fasting glucose [30]
The Scientist's Toolkit: Research Reagent Solutions
Table 5: Essential Methodological Components for Dietary Pattern Research
| Research Component | Function/Application | Implementation Examples |
|---|---|---|
| Dietary Assessment Tools | ||
| 24-Hour Dietary Recalls | Gold standard for detailed intake assessment; multiple recalls needed to estimate usual intake | Automated self-administered 24-h recall (ASA24); interviewer-administered recalls |
| Food Frequency Questionnaires (FFQs) | Assess usual dietary intake over extended periods; lower respondent burden | Block FFQ, Harvard FFQ, Diet History Questionnaire II |
| Food Diaries/Records | Real-time recording of food consumption; reduces recall bias | 3-day food diaries with household measures; digital food recording apps |
| Validation Instruments | ||
| Biomarker Measurements | Objective validation of dietary intake | Plasma carotenoids (fruit/vegetable intake), erythrocyte fatty acids (fish/fat quality), urinary sodium (sodium intake) |
| Recovery Biomarkers | Quantify measurement error in self-report | Doubly labeled water (energy intake), urinary nitrogen (protein intake) |
| Statistical Packages | ||
| Classification Algorithms | Compare predictive accuracy of dietary patterns | Multiple logistic regression, naïve Bayes, decision trees, support vector machines [26] |
| Dimension Reduction Methods | Identify a posteriori dietary patterns | Principal component analysis (PCA), factor analysis, treelet transform, reduced rank regression [11] |
| Reliability Analysis | Assess stability of dietary measurements | Intraclass correlation coefficients, kappa statistics, test-retest reliability [29] [10] |
The Healthy Eating Index and Mediterranean Diet Score represent sophisticated a priori methodologies that translate complex dietary concepts into quantifiable research variables. While both approaches evaluate overall diet quality, they emerge from distinct philosophical foundations—the HEI from evidence-based dietary guidelines and the MDS from traditional eating patterns associated with health benefits.
For researchers and drug development professionals, selection between these instruments should be guided by specific research questions and population characteristics. The HEI offers advantages for policy-relevant research in US populations and when alignment with Dietary Guidelines is a primary concern. The MDS provides strong predictive validity for chronic disease outcomes, particularly in Mediterranean contexts or when investigating inflammatory pathways.
Future methodological development should focus on enhancing cross-population comparability, integrating biological validation through biomarkers, and developing hybrid approaches that leverage the strengths of both a priori and a posteriori methods. As nutritional science evolves, these a priori dietary patterns will continue to serve as vital tools for understanding the complex relationship between diet, health, and disease.
In nutritional epidemiology, the analysis of dietary patterns has progressively shifted focus from single nutrients to the holistic combination of foods consumed, recognizing the complex interactions and cumulative effects of overall diet on health outcomes. Within this paradigm, a posteriori methods represent data-driven approaches that derive dietary patterns empirically from existing dietary consumption data, without relying on predetermined nutritional hypotheses [7]. Among these techniques, Principal Component Analysis (PCA) and Exploratory Factor Analysis (EFA) have emerged as the most extensively employed methods for identifying population-specific dietary patterns [7]. These methods enable researchers to reduce the dimensionality of complex dietary data and identify underlying structures that reflect actual eating habits within study populations. The application of these techniques within the broader framework of a priori versus a posteriori dietary pattern research provides valuable insights into how empirical data can complement hypothesis-driven approaches to nutritional science, offering a comprehensive understanding of diet-disease relationships.
Theoretical Foundations: PCA and EFA in Nutritional Epidemiology
Principal Component Analysis (PCA)
PCA is a multivariate statistical technique designed to explain the maximum amount of variance in observed variables through a smaller number of composite variables called principal components. In nutritional epidemiology, PCA transforms a set of possibly correlated food group variables into a new set of uncorrelated principal components that are linear combinations of the original variables [7]. These components are ordered such that the first component accounts for the largest possible variance in the data, with each succeeding component explaining the remaining variance under the constraint of being orthogonal to preceding components. The mathematical objective of PCA is the eigen-decomposition of the covariance or correlation matrix of the original food group variables, producing eigenvectors (which determine the direction of the components) and eigenvalues (which indicate the magnitude of variance captured by each component) [32]. In dietary pattern analysis, food items are typically pre-grouped into food groups before calculating principal components through optimal weighted linear combinations based on their correlation structure [7].
Exploratory Factor Analysis (EFA)
EFA is a related but theoretically distinct method that aims to identify the latent constructs (factors) that explain the covariation among observed food group variables. Unlike PCA, which focuses on total variance, EFA differentiates between common variance (shared among multiple variables) and unique variance (specific to individual variables plus error) [33]. The fundamental factor analysis model represents each observed variable as a linear combination of common factors and a unique factor, with the objective of explaining the intercorrelations among variables through a smaller number of underlying dimensions [34]. EFA operates under the assumption that the covariation observed in dietary data results from these latent dietary patterns that influence consumption of multiple related food groups simultaneously. This method is particularly valuable when researchers hypothesize that unobservable constructs (such as "traditional eating pattern" or "health-conscious pattern") drive the correlations among observed food consumption variables.
Key Theoretical Distinctions
While PCA and EFA are often used interchangeably in nutritional literature, they serve different analytical purposes and operate under distinct theoretical frameworks, as summarized in Table 1.
Table 1: Theoretical and Methodological Comparison Between PCA and EFA
| Feature | Principal Component Analysis (PCA) | Exploratory Factor Analysis (EFA) |
|---|---|---|
| Primary Objective | Dimensionality reduction and variance maximization [32] | Identification of latent constructs explaining covariation [32] |
| Variance Focus | Captures total variance in observed variables [32] | Explains shared variance among observed variables [32] |
| Theoretical Model | No underlying statistical model; mathematical transformation [34] | Based on a statistical model with common and unique factors [34] |
| Variable Representation | Components are linear combinations of all food groups [7] | Observed variables are linear combinations of latent factors plus error terms [33] |
| Assumptions | No assumptions about underlying structure [32] | Assumes existence of latent variables influencing observed variables [32] |
| Factor Interpretation | Components represent dietary patterns as empirical combinations | Factors represent latent constructs influencing food choices |
Methodological Protocols for Dietary Pattern Analysis
Data Preprocessing and Preparation
The initial phase in both PCA and EFA involves careful data preprocessing to ensure appropriate variable representation. Dietary data typically comes from food frequency questionnaires, 24-hour recalls, or dietary records, which must be converted into standardized food group variables. The process involves:
Food Grouping: Individual food items are aggregated into meaningful food groups based on nutritional characteristics or culinary use [35]. For example, a study on hypertension risk grouped 147 food items into 20 food groups for analysis [35].
Handling of Zero Consumption: For food groups with low consumption frequency, specific categorization approaches are required. In PCA applications, food groups with <25% consumers are often categorized as binary variables (non-consumers vs. consumers), while those with >25% consumers may be categorized as three-level variables (non-consumers and consumers with dietary intake above/below median) [35].
Correlation Matrix Assessment: The suitability of data for factor analysis is evaluated using tests such as the Kaiser-Meyer-Olkin measure of sampling adequacy and Bartlett's test of sphericity [35].
Analytical Procedure for PCA
The implementation of PCA in dietary pattern analysis follows a structured protocol:
Extraction of Components: Principal components are extracted from the correlation matrix of food groups, with the first component explaining the maximum possible variance [7].
Determination of Number of Components: The number of components to retain is determined using multiple criteria, including:
- Eigenvalue-greater-than-one rule (Kaiser's criterion)
- Scree plot analysis
- Interpretable variance percentage (typically >5% per component)
- Conceptual interpretability [7]
Rotation: Varimax orthogonal rotation is commonly applied to achieve simpler structure with greater interpretability by maximizing high loadings and minimizing low loadings [35].
Interpretation and Labeling: Components are interpreted based on food groups with high factor loadings (typically |loading| >0.2 to |loading| >0.3), and are named according to the predominant food groups [35].
A study on dietary patterns and hypertension provides a representative example, where PCA identified five dietary patterns from 19 food groups using a polychoric correlation matrix and varimax rotation [35].
Analytical Procedure for EFA
The EFA protocol shares similarities with PCA but incorporates distinct elements:
Factor Extraction: Multiple extraction methods are available, including principal axis factoring, maximum likelihood, and generalized least squares, each with different statistical properties [33].
Determination of Number of Factors: Similar criteria as PCA are applied, with parallel analysis increasingly recommended as a robust method [33].
Rotation: Both orthogonal (varimax) and oblique (promax) rotations may be employed, with oblique rotations allowing for correlated factors, which often better reflects reality in dietary patterns [33].
Factor Interpretation: Factors are interpreted based on pattern coefficients (loadings), with attention to the underlying constructs that explain covariation among food groups.
Methodological Considerations in Pattern Retention
A critical challenge in both PCA and EFA is determining the optimal number of patterns to retain. Research indicates that this decision significantly impacts resulting patterns and their associations with health outcomes. A study on dietary pattern reproducibility found that for PCA, the 3-component solution demonstrated best replication, though all solutions contained at least one poorly confirmed component [36]. Importantly, different pattern solutions varied in their food-group composition and associations with coronary heart disease, highlighting the consequence of retention decisions [36]. For cluster analysis, an alternative a posteriori method, most quantitative criteria identified the 2-cluster solution as optimal, and associations with disease outcome were comparable across different cluster solutions, suggesting greater stability than PCA-derived patterns [36].
Applications in Nutritional Research: Comparative Evidence
Dietary Patterns and Health Outcomes
Both PCA and EFA have been extensively applied in nutritional epidemiology to identify dietary patterns associated with various health outcomes. The following table summarizes key findings from recent studies employing these methods:
Table 2: Applications of PCA and EFA in Dietary Pattern Research
| Study Population | Method Used | Patterns Identified | Health Associations |
|---|---|---|---|
| Chinese adults (n=3892) [35] | PCA | Five dietary patterns | No significant association with hypertension risk |
| Chinese adults (n=3892) [35] | Principal Balances Analysis (PBA) | Five dietary patterns | Coarse cereals pattern inversely associated with hypertension (OR=0.74) |
| Iranian obese women (n=376) [37] | PCA | Three dietary patterns | Plant-based pattern associated with higher fat-free mass index |
| Iranian obese women (n=376) [37] | Partial Least Squares (PLS) | Two dietary patterns | Plant-based pattern associated with lower FBS, DBP, and CRP |
| Greek adults (n=480) [38] | PCA | Five dietary patterns (processed foods, plant-based, Western-type, healthy, alcohol-coffee) | Associations with personality traits; openness predicted healthy and plant-based patterns |
Pattern Reproducibility Across Populations
The reproducibility of PCA-derived dietary patterns across different populations has been systematically evaluated. A review of PCA-derived patterns in Japanese adults examined 285 different dietary patterns from 65 articles [39]. While certain patterns like "Western" and "traditional Japanese" showed low congruence coefficients (median CC=0.44 and 0.31, respectively), "healthy" and "Japanese" patterns demonstrated higher reproducibility (median CC=0.89 and 0.80, respectively) [39]. These findings highlight that while some major dietary patterns are relatively reproducible across different populations within a country, others are population-specific, emphasizing the need for careful interpretation of PCA-derived patterns.
Comparison with Emerging Methodologies
Recent research has compared traditional PCA with emerging analytical approaches. A study comparing PCA with principal balances analysis (PBA), a compositional data method, found that PBA patterns included several food groups with zero loadings, resulting in clearer interpretability and accounting for a higher percentage of variance in food intake [35]. Similarly, a comparison of PCA, reduced-rank regression (RRR), and partial least squares (PLS) found that PLS and RRR-derived patterns explained greater variance in cardiometabolic outcomes (11.62% and 25.28%, respectively) compared to PCA (1.05%), while PCA patterns explained greater variance in food groups (22.81%) [37].
Table 3: Essential Methodological Components for Dietary Pattern Analysis
| Research Component | Function/Description | Implementation Considerations |
|---|---|---|
| Dietary Assessment Tool | Food Frequency Questionnaire (FFQ), 24-hour recall, or food records to collect intake data | Should be validated for the target population; FFQ most common for pattern analysis [35] |
| Food Grouping Schema | System for aggregating individual food items into meaningful categories | Based on nutritional similarity or culinary use; significantly impacts resulting patterns [35] |
| Statistical Software | Platforms for implementing PCA/EFA (R, SAS, SPSS, STATA) | R offers extensive packages for dietary pattern analysis; SAS PROC FACTOR for EFA [7] |
| Rotation Methods | Mathematical techniques to improve interpretability of patterns | Varimax (orthogonal) or Promax (oblique); choice depends on expected correlation between patterns [35] |
| Retention Criteria Tools | Statistical tests to determine number of patterns to retain | Parallel analysis, scree plots, eigenvalue >1 rule; parallel analysis often most robust [36] |
| Validation Methods | Techniques to assess robustness of identified patterns | Split-sample replication, confirmatory factor analysis, stability coefficients [36] |
Advanced Applications and Hybrid Approaches
Integration with Health Outcomes
Advanced applications of a posteriori methods have evolved to incorporate health outcomes more directly into the pattern identification process. Reduced Rank Regression (RRR) and Partial Least Squares (PLS) represent hybrid approaches that identify dietary patterns that maximize explained variation in both food intake and response variables (e.g., nutrient intake or biomarkers) related to specific health outcomes [37]. In a comparison of these methods, PLS was found to be more appropriate than PCA for identifying dietary patterns associated with cardiometabolic risk factors, explaining substantially more variance in outcomes while maintaining reasonable variance explanation in food groups [37].
Compositional Data Analysis (CoDA)
Recognizing that dietary data are inherently compositional (parts of a whole that sum to a constant total), Compositional Data Analysis has emerged as an alternative framework for dietary pattern analysis [35]. CoDA methods, particularly Principal Balances Analysis (PBA), address the compositional nature of dietary data by focusing on log-ratio transformations between food groups [35]. Studies comparing PCA and PBA have found that PBA patterns tend to be more clearly interpretable, include food groups with zero loadings, and account for a higher percentage of variance in food intake [35].
PCA and EFA represent foundational a posteriori techniques that have significantly advanced the field of dietary pattern analysis by enabling data-driven identification of population eating patterns. While often used interchangeably, these methods possess distinct theoretical foundations and analytical objectives that influence their application and interpretation in nutritional epidemiology. Evidence suggests that methodological decisions, particularly regarding the number of patterns to retain, significantly impact the resulting patterns and their associations with health outcomes [36]. The emergence of hybrid methods like RRR and PLS, along with compositional approaches like PBA, offers promising alternatives that may address certain limitations of traditional PCA and EFA [35] [37].
Future methodological development should focus on improving the reproducibility and validity of derived patterns, establishing clearer guidelines for methodological decisions, and integrating advances in data science and machine learning. As the field evolves, the complementary use of multiple analytical approaches, within the broader framework of both a priori and a posteriori methods, will provide the most comprehensive understanding of how overall dietary patterns influence health and disease.
Dietary pattern analysis represents a pivotal shift in nutritional epidemiology, moving beyond the limitations of single-nutrient studies to capture the complex interplay of foods and nutrients consumed in combination. Within this field, a fundamental distinction exists between a priori (hypothesis-driven) and a posteriori (data-driven) approaches. A priori methods, such as dietary quality scores, evaluate adherence to predefined dietary guidelines but may miss novel patterns relevant to disease. A posteriori methods, including Principal Component Analysis (PCA) and cluster analysis, derive patterns solely from intake data but may not optimally predict health outcomes [7]. Hybrid methods, particularly Reduced Rank Regression (RRR) and the Treelet Transform (TT), have emerged as sophisticated analytical bridges between these paradigms. RRR incorporates prior knowledge about diet-disease pathways while remaining grounded in observed dietary data [40] [41], whereas TT enhances traditional data-driven approaches by producing more interpretable patterns through variable clustering [42]. These advanced techniques offer powerful solutions for identifying dietary patterns that are both mechanistically linked to health outcomes and representative of population eating behaviors, making them invaluable for researchers and drug development professionals investigating diet-disease relationships.
Reduced Rank Regression (RRR)
Conceptual Foundation and Mathematical Basis
Reduced Rank Regression is a hybrid method that combines elements of a priori and a posteriori approaches. Its fundamental principle is to identify linear combinations of predictor variables (food groups) that maximally explain the variation in a set of response variables (intermediate markers) [7]. These response variables, chosen based on prior knowledge, are biomarkers or nutrients believed to be on the causal pathway between diet and the health outcome of interest [40] [41]. Mathematically, RRR solves a dimensionality reduction problem where it seeks factors that maximize the explained variation in the response variables, creating dietary patterns that are directly relevant to the disease pathogenesis pathways under investigation [7].
The number of dietary patterns derivable through RRR is constrained by the number of response variables specified. For instance, a study using four nutrient response variables (protein, carbohydrates, saturated fats, and unsaturated fats) derived four distinct dietary patterns [40]. This methodological characteristic ensures that the derived patterns have direct physiological relevance to the chosen intermediate markers.
Experimental Implementation Protocol
Implementing RRR involves a structured multi-stage process:
Stage 1: Variable Selection and Preparation
- Predictor Variables: Collapse dietary intake data into logically grouped food items. For example, a 2024 NHANES analysis used 26 food groups including citrus fruits, dark green vegetables, whole grains, meat, fish, dairy products, and added sugars [40].
- Response Variables: Select intermediate markers based on established literature. For instance, studies have used:
Stage 2: Model Execution
- Apply RRR using statistical software (SAS, R, or STATA) to derive factor loadings for each food group on the extracted patterns.
- The first pattern explains the maximum variation in response variables, with subsequent patterns explaining residual variation orthogonally.
Stage 3: Pattern Interpretation and Validation
- Interpret patterns by examining food groups with high absolute loading values (typically ≥|0.17|) [43].
- Validate patterns through association testing with health outcomes using regression models, often expressing results as β-coefficients or odds ratios across pattern score quartiles.
Table 1: Key Response Variables Used in RRR Studies and Their Rationale
| Health Outcome | Response Variables | Biological Rationale | Study Example |
|---|---|---|---|
| Inflammation & Central Obesity | Protein, Carbohydrates, Saturated Fats, Unsaturated Fats | Macronutrient composition influences metabolic pathways and adiposity | [40] |
| Depressive Symptoms | EPA+DHA, Folate, Mg, Zn | Nutrients with anti-inflammatory and neuroprotective properties | [41] |
| Adolescent Obesity | Dietary energy density, Fiber density, % energy from fat | Direct determinants of energy balance and fat accumulation | [43] |
Research Reagent Solutions
Table 2: Essential Methodological Components for RRR Implementation
| Research Component | Function & Specification | Implementation Example |
|---|---|---|
| Dietary Assessment Tool | 24-hour recalls (Automated Multiple-Pass Method) or validated Food Frequency Questionnaires (FFQ) | NHANES used 24-hour recall data [40]; InCHIANTI study used 188-item FFQ [41] |
| Nutrient Database | Standardized food composition database for calculating nutrient intakes | USDA Food and Nutrient Database for Dietary Studies [40] |
| Food Grouping Scheme | System for collapsing individual foods into meaningful categories | 37 USDA Food Patterns Equivalents Database components [40] |
| Response Variables | Nutrients or biomarkers on causal pathway to health outcome | Macronutrients for obesity studies; micronutrients for mental health studies [40] [41] |
| Statistical Software Package | Program capable of implementing RRR algorithm | SAS, R, or STATA with specialized macros [7] |
Application Workflow
Empirical Applications and Findings
RRR has demonstrated substantial utility across diverse research contexts. A 2024 analysis of NHANES data (1999-2018, n=41,849) identified four distinct macronutrient-based patterns, with the high saturated fat pattern positively associated with waist circumference (βQ5vsQ1=1.71; 95% CI: 0.97, 2.44) and C-reactive protein (βQ5vsQ1=0.37; 95% CI: 0.26, 0.47), indicating links to both central obesity and systemic inflammation [40]. The same study revealed socioeconomic patterning, with higher economic status associated with high fat, low carbohydrate (βHighVsLow=0.22; 95% CI: 0.16, 0.28) and high protein patterns (βHighVsLow=0.07; 95% CI: 0.03, 0.11) [40].
In mental health research, the InCHIANTI study (n=1,362) applied RRR with EPA+DHA, folate, magnesium, and zinc as responses, deriving a "typical Tuscan dietary pattern" rich in vegetables, olive oil, grains, fruit, fish, and moderate in wine and red/processed meat. This pattern was inversely associated with depressive symptoms over 9 years (Q1 v. Q4, B -1.78; 95% CI -3.7, -0.38) [41].
Cross-country validation studies demonstrate RRR's reproducibility. Research comparing European and Australian adolescents identified similar "energy dense, high fat, low fibre" patterns in both populations, characterized by higher biscuits/cakes, chocolate/confectionery, crisps, sugar-sweetened beverages, and lower yogurt, high-fibre bread, vegetables, and fruit. This pattern was inversely associated with BMI z-scores in adolescent boys [43].
Treelet Transform (TT)
Conceptual Foundation and Mathematical Basis
The Treelet Transform represents an innovative multivariate statistical method that combines the quantitative pattern extraction capabilities of PCA with the interpretational advantages of cluster analysis [42]. Unlike traditional PCA, which produces components involving all original variables, TT generates patterns comprising only naturally grouped subsets of variables, enhancing interpretability without sacrificing explanatory power [44] [42]. The algorithm operates through an iterative process that identifies similar variables and merges them, producing a hierarchical tree structure and a corresponding set of basis functions that are both sparse and localized [42].
Mathematically, TT begins by computing the sample covariance matrix of the dietary variables, then proceeds through a series of steps where at each level, the two most similar variables are clustered together. This process generates a hierarchical tree with associated orthonormal basis functions that become increasingly sparse at higher levels of the tree. The resulting components capture the major sources of variance in the data while naturally grouping correlated food items together, making them more interpretable than traditional PCA components [44].
Experimental Implementation Protocol
Stage 1: Data Preparation and Similarity Measurement
- Standardize all food group variables to mean zero and unit variance.
- Compute the covariance matrix of all food group variables.
- Calculate similarity measures between all variable pairs, typically using correlation coefficients.
Stage 2: Iterative Clustering and Transformation
- Identify the two most similar variables based on correlation coefficients.
- Apply Jacobi rotation to these variables, creating a new sparse basis.
- Repeat the process, building a hierarchical tree structure.
Stage 3: Component Selection and Interpretation
- Select the number of components to retain based on scree plots or explained variance.
- Interpret components by examining food groups with high loadings within each clustered subset.
- Name patterns according to the predominant food groups within each cluster.
Research Reagent Solutions
Table 3: Methodological Requirements for Treelet Transform Implementation
| Research Component | Function & Specification | Implementation Considerations |
|---|---|---|
| Dietary Variables | Standardized food group intake data | Similar preprocessing as for PCA |
| Similarity Metric | Correlation coefficient matrix | Measures variable relationships for clustering |
| Treelet Algorithm | Software implementation of TT | Specialized packages in R or Python |
| Visualization Tools | Tree structure plotting capabilities | For interpreting hierarchical clustering |
| Component Selection Criteria | Variance-based or interpretability-focused | Similar to PCA scree plots |
Analytical Workflow
Empirical Applications and Findings
In a pioneering application, TT was compared with PCA for identifying dietary patterns associated with myocardial infarction risk in a Danish cohort of 26,155 men [42]. The researchers derived seven patterns using each method, finding that TT patterns described almost as much variation as PCA patterns (comparable explanatory power) but with significantly clearer interpretation. When examining myocardial infarction risk over a median 11.9 years of follow-up (1,523 incident cases), the significant risk factors were comparable whether models were based on PCA or TT factors, demonstrating that TT maintains predictive validity while enhancing interpretability [42].
The key advantage observed was that TT naturally grouped specific foods together, such as different types of vegetables or meat products, creating patterns that reflected logical dietary combinations rather than abstract mathematical constructs. This clustering approach mirrors how nutritionists conceptually group foods, making the results more accessible for translation into dietary recommendations [44] [42].
Comparative Analysis and Methodological Integration
Relative Advantages and Implementation Considerations
Table 4: Comparative Analysis of Advanced Dietary Pattern Methods
| Methodological Characteristic | Reduced Rank Regression (RRR) | Treelet Transform (TT) | Traditional PCA |
|---|---|---|---|
| Analytical Approach | Hybrid (a priori + a posteriori) | Enhanced data-driven | Pure data-driven |
| Key Input Requirements | Predictor food groups + response variables | Food groups only | Food groups only |
| Pattern Interpretation | Based on response variables + food loadings | Natural variable clusters | Mathematical constructs |
| Health Outcome Connection | Direct via intermediate markers | Indirect via pattern-health testing | Indirect via pattern-health testing |
| Reproducibility Across Populations | Moderate (depends on response consistency) | High when food cultures similar | Variable |
| Primary Advantage | Optimized for specific health outcomes | Enhanced interpretability | Maximum variance explanation |
| Primary Limitation | Dependent on intermediate marker knowledge | Less established in nutrition research | Abstract, difficult interpretation |
Integration within Dietary Patterns Research Paradigm
RRR and TT occupy distinct but complementary positions within the methodological spectrum of dietary pattern analysis. RRR's strength lies in its incorporation of biological pathways through response variables, creating a direct bridge between dietary intake and disease mechanisms [40] [41]. This makes it particularly valuable for drug development professionals investigating specific metabolic pathways or nutrient-disease relationships. TT, conversely, enhances traditional exploratory methods by producing more intuitively understandable patterns, facilitating translation of findings into public health recommendations and dietary guidelines [42].
Both methods address limitations of pure a priori or a posteriori approaches. RRR mitigates the potential circularity of completely data-driven methods by incorporating prior knowledge of biological mechanisms, while TT addresses the interpretability challenges of traditional factor analysis without requiring predetermined hypotheses [44] [7]. For comprehensive research programs, these methods can be employed sequentially: using TT for initial pattern exploration in unfamiliar populations, then applying RRR to test specific mechanistic hypotheses regarding identified patterns and health outcomes of interest.
Reduced Rank Regression and Treelet Transform represent significant methodological advancements in dietary pattern analysis, each offering unique solutions to the limitations of traditional approaches. RRR provides a powerful hypothesis-guided framework for investigating specific diet-disease pathways, while TT enhances pattern interpretability without sacrificing statistical rigor. For researchers and drug development professionals, these methods enable more biologically plausible and translatable investigations of diet-health relationships, strengthening the evidence base for nutritional interventions and public health guidelines. As dietary patterns research continues to evolve, further development and application of these sophisticated analytical techniques will be crucial for unraveling the complex relationships between diet, health, and disease.
Dietary assessment is a fundamental component of nutritional epidemiology, providing the critical data necessary to investigate links between diet and health outcomes. The accurate measurement of food and nutrient intake presents significant methodological challenges due to the complexity of human diets, day-to-day variability in consumption, and inherent limitations of self-reported data. Within the context of dietary pattern analysis—a research approach that considers the combined effects of foods and nutrients—assessment tools provide the foundational data for both a priori patterns (hypothesis-driven, index-based patterns like the Mediterranean diet) and a posteriori patterns (data-driven patterns derived statistically, such as "Western" or "prudent" patterns) [4]. This technical guide examines the core tools, from traditional Food Frequency Questionnaires (FFQs) to modern digital platforms, and details the data processing pipelines that transform raw dietary data into meaningful research variables.
Dietary assessment methods can be broadly categorized by their timeframe (short-term vs. long-term) and approach (open-ended vs. closed-ended). The following table summarizes the primary tools used in research settings, their core methodologies, and key applications.
Table 1: Classification of Major Dietary Assessment Tools
| Tool Type | Primary Method | Timeframe Assessed | Key Outputs | Primary Research Use |
|---|---|---|---|---|
| Food Frequency Questionnaire (FFQ) [45] | Pre-defined food list with frequency responses | Habitual intake (months to a year) | Average daily nutrient and food group intake | A posteriori pattern derivation; A priori pattern adherence |
| Food Record/Diary [46] | Real-time recording of all foods/beverages consumed | Short-term (typically 3-7 days) | Detailed daily intake data for nutrients and foods | Validation standard; Intake quantification |
| 24-Hour Dietary Recall [47] | Structured interview to recall previous day's intake | Short-term (single or multiple days) | Detailed single-day intake data | Population mean intake estimates; A posteriori patterns |
| Diet Quality Photo Navigation (DQPN) [46] | Pattern recognition via image selection | Habitual intake | Overall diet quality score (e.g., Healthy Eating Index) | Rapid diet quality screening in clinical settings |
The Food Frequency Questionnaire (FFQ) is designed to capture habitual dietary intake over an extended period, typically the past year [45]. Its closed-ended format, featuring a pre-defined list of foods and standard portion sizes, facilitates efficient data collection in large-scale epidemiological studies. In contrast, Food Records involve the real-time documentation of all foods and beverages consumed as they are eaten, providing detailed, quantitative data without relying on memory [46]. The 24-Hour Dietary Recall is a structured interview that uses multiple passes to guide participants through recalling all dietary intake from the previous 24 hours [47]. A prominent example is the Automated Self-Administered 24-hour (ASA24) tool, a web-based platform freely provided by the National Cancer Institute that automates the recall process for researchers [47]. Emerging tools like Diet Quality Photo Navigation (DQPN) represent a shift toward pattern recognition, where users identify their habitual diet from a series of images, yielding a rapid assessment of overall diet quality aligned with indices like the Healthy Eating Index [46].
Dietary Assessment in A Priori and A Posteriori Pattern Analysis
The choice of dietary assessment tool directly influences the approach to dietary pattern analysis.
A Priori Pattern Analysis: This hypothesis-driven approach evaluates adherence to pre-defined dietary patterns reflective of a specific dietary philosophy or guideline. Examples include the Mediterranean Diet, Healthy Eating Index (HEI), and other healthy dietary indices [4]. These patterns are defined by scoring algorithms applied to intake data, typically collected via FFQs, which are well-suited to capturing the habitual, long-term intake relevant to such indices [21]. For instance, a 2025 meta-analysis confirmed that high adherence to the Mediterranean diet (an a priori pattern) is associated with a significantly reduced risk of Parkinson's disease (RR = 0.87; 95%CI: 0.78–0.97) [4].
A Posteriori Pattern Analysis: This data-driven approach uses statistical methods like factor or cluster analysis on dietary intake data to identify patterns that exist within a study population [4]. These emergent patterns, such as "Western" or "Healthy" patterns, are derived from the correlations between foods consumed. While FFQs are commonly used, 24-hour recalls and food records provide the detailed, quantitative data necessary for this analysis. The same 2025 meta-analysis found that a data-driven "Western dietary pattern" was associated with a 54% increased risk of Parkinson's disease (RR = 1.54; 95%CI: 1.10–2.15) [4].
Experimental Protocols for Tool Validation
The validation of dietary assessment tools against a reference method is a critical step in establishing their utility for research. The following are detailed protocols from recent validation studies.
Protocol 1: Comparative Validation of a Novel Digital Tool
A 2023 study validated the Diet ID tool, which uses Diet Quality Photo Navigation (DQPN), against two traditional methods [46].
- Objective: To assess the validity of Diet ID in measuring diet quality, food group, and nutrient intake against a Food Frequency Questionnaire (FFQ) and a 3-day Food Record (FR), and to evaluate its test-retest reliability [46].
- Study Population: 90 US adults were recruited, with 58 completing all three dietary assessments. The mean age was 38 years, and 64% were male [46].
- Intervention and Sequence:
- Week 1: Participants completed the DQPN tool and a 3-day FR (using the ASA24 system), covering 2 weekdays and 1 weekend day.
- Week 2: Participants completed the FFQ (using the Dietary History Questionnaire III).
- Week 3: Participants repeated the DQPN tool to assess reliability [46].
- Data Analysis: Pearson correlations were generated to compare diet quality (as measured by the Healthy Eating Index 2015), nutrient intakes, and food group intakes between the tools. Test-retest reliability for DQPN was also calculated using Pearson correlation [46].
- Key Findings: DQPN showed strong correlations with the FFQ and FR for overall diet quality (r=0.58 and r=0.56, respectively; p<0.001). Test-retest reliability for DQPN was high (r=0.70, p<0.0001) [46].
Protocol 2: Validation of a Short FFQ in a Specialized Population
A 2025 study validated a short 14-item FFQ against weighted food records in the context of intermittent fasting [48].
- Objective: To assess the validity of a short, semi-quantitative FFQ for use in clinical trials investigating intermittent fasting regimes [48].
- Study Population: 15 adults (7 women, 8 men) with a median age of 29 years participating in a controlled trial on religious Bahá'í fasting and time-restricted eating [48].
- Intervention and Data Collection:
- Food Records: Participants kept weighted food records for one week at baseline and for 19-21 days during the intervention. These records were analyzed using PRODI, professional dietary assessment software.
- FFQ: Participants completed the short FFQ once at baseline and twice during the intervention [48].
- Data Analysis: The validity of the FFQ was assessed using correlation analysis and method agreement analysis, including Bland-Altman plots for continuous data [48].
- Key Findings: Correlation coefficients for individual items ranged from 0.189 (tendency to snack) to 0.893 (meat consumption). While most questions were valid, the FFQ was unreliable for assessing snacking behavior and whole-grain consumption. Furthermore, the FFQ could not feasibly analyze changes in energy and macronutrient intake, which were quantified using the food records [48].
Data Processing and Analytical Workflows
The transformation of raw dietary data into analyzable format involves a multi-stage pipeline. The workflow differs significantly between a priori and a posteriori analyses.
Diagram: Dietary Data Processing and Analysis Workflow
From Raw Questionnaires to Analyzable Data
The data processing pipeline for an FFQ, as implemented in tools like the open-source FETA software used in the EPIC-Norfolk study, involves several standardized steps [45]:
- Frequency Conversion: Each frequency category (e.g., "once per week") is converted to a daily multiplier (e.g., 1/7 ≈ 0.14) [45].
- Portion Size Application: The daily multiplier is applied to a standardized portion size for each food item to calculate an average daily food weight consumed [45].
- Nutrient Calculation: The daily food weight is multiplied by the nutrient composition per gram (from databases like FNDDS or NDSR) to determine the nutrient intake for each food item [46] [45].
- Data Aggregation: Nutrient intakes from all food items are summed to obtain an individual's average daily intake for each nutrient [45].
- Quality Control: Checks are performed for missing data and implausible energy intakes, often by comparing the ratio of reported energy intake to estimated basal metabolic rate [45].
For data from 24-hour recalls and food records, the USDA utilizes specialized databases like the Food and Nutrient Database for Dietary Studies (FNDDS) and the Food Pattern Equivalents Database (FPED) to convert reported foods into nutrients and food group components, respectively [49].
Table 2: Essential Research Reagents and Resources for Dietary Assessment
| Resource Name | Type/Function | Primary Use Case | Key Features & Database |
|---|---|---|---|
| ASA24 (Automated Self-Administered 24-h Assessment) [47] | Web-based 24-h recall & food record tool | Population intake estimation; Validation studies | Automatically coded; Uses USDA's FNDDS |
| DHQ III (Dietary History Questionnaire III) [46] | Web-based Food Frequency Questionnaire (FFQ) | Habitual intake assessment in large cohorts | 135 food/beverage items; Uses FNDDS & NDSR |
| Diet ID [46] | Digital, pattern recognition tool | Rapid diet quality screening in clinical care | Yields HEI score; ~5 min completion |
| USDA FNDDS (Food & Nutrient Database for Dietary Studies) [49] | Nutrient composition database | Provides nutrient values for foods in WWEIA, NHANES | Contains ~7,000 foods; 64 nutrients |
| USDA FPED (Food Pattern Equivalents Database) [49] | Food group composition database | Converts foods into USDA Food Pattern components | Essential for assessing guideline adherence |
| PRODI [48] | Professional dietary analysis software | Analysis of detailed food records in clinical trials | Used with weighted food records |
| FETA (Frequency Energy and Tailored Analysis) [45] | Open-source nutrient calculation code | Processing FFQ data in research studies | Converts frequency data to daily intake |
Dietary assessment remains a challenging yet evolving field. Traditional tools like FFQs and food records, with their well-understood strengths and limitations, continue to be pillars of nutritional epidemiology, providing the data that fuels both a priori and a posteriori dietary pattern research. The ongoing digital transformation, exemplified by tools like ASA24 and Diet ID, promises improved scalability and reduced participant burden, though it does not fully solve inherent issues like misreporting [50]. The choice of tool must be carefully aligned with the research question, considering the trade-offs between detail and scale, and between hypothesis-testing and exploratory analysis. As research progresses, particularly in specialized populations, rigorous validation—including against biochemical biomarkers where appropriate—remains paramount to generating reliable evidence linking diet to health [51].
Dietary pattern analysis provides a holistic approach to understanding the relationship between diet and health outcomes in specific populations. This whitepaper explores the application of a priori and a posteriori dietary pattern analysis in women of childbearing age, a critical population where nutritional status has profound implications for maternal health and intergenerational well-being. Through examination of methodological approaches, key case studies, and technical protocols, we provide researchers with a framework for conducting robust dietary pattern analysis. Our findings demonstrate that both methodological approaches offer distinct insights, with a posteriori methods revealing population-specific patterns and a priori methods enabling standardized comparison across studies. The evidence consistently identifies "Western" and "prudent" patterns across diverse populations of women, with socio-demographic factors significantly influencing dietary adherence. This technical guide serves as an essential resource for nutritional epidemiologists and public health researchers working to advance maternal nutrition science.
Dietary pattern analysis has emerged as a fundamental methodology in nutritional epidemiology, addressing the complex interactions between multiple foods and nutrients consumed in combination. This approach recognizes that individuals consume meals consisting of various food items with synergistic or antagonistic effects on health, moving beyond the limitations of single-nutrient studies [52]. The analysis of dietary patterns is particularly valuable for developing comprehensive public health recommendations and understanding the multifaceted relationship between diet and disease risk.
The two primary methodological approaches for dietary pattern analysis are a priori (hypothesis-driven) and a posteriori (exploratory) methods. A priori patterns are based on predefined dietary indices or guidelines, such as the Mediterranean Diet Score (MDS), Dietary Approaches to Stop Hypertension (DASH), or Healthy Eating Index (HEI) [22]. These methods apply existing nutritional knowledge to evaluate adherence to dietary patterns with established health benefits. In contrast, a posteriori methods use multivariate statistical techniques to derive patterns empirically from dietary intake data without predefined hypotheses, identifying habitual consumption patterns within specific study populations [20].
Women of childbearing age represent a particularly important population for dietary pattern research due to the critical role of nutrition in reproductive health, pregnancy outcomes, and long-term offspring health [53]. Nutritional status during this life stage has implications for fertility, fetal development, and the prevention of gestational complications, making dietary assessment methodologies particularly relevant for this demographic. This technical guide examines the application of both a priori and a posteriori dietary pattern analysis in women of childbearing age, providing researchers with methodological frameworks, case studies, and technical protocols to advance research in this field.
Methodological Approaches: A Priori vs. A Posteriori Analysis
A Priori Dietary Pattern Analysis
A priori dietary pattern analysis evaluates adherence to predefined dietary patterns based on existing nutritional knowledge, dietary guidelines, or culinary traditions associated with health benefits. This hypothesis-driven approach allows researchers to test specific dietary patterns against health outcomes of interest, facilitating comparisons across studies and populations. The methodological framework involves constructing dietary scores or indices where higher values indicate better adherence to the target pattern [22].
The most commonly applied a priori patterns include the Mediterranean Diet Score (MDS), Dietary Approaches to Stop Hypertension (DASH), and Healthy Eating Index (HEI). The alternative Mediterranean Diet (aMED) score assesses adherence to nine dietary components, including vegetables, legumes, fruits, nuts, whole grains, fish, monounsaturated-to-saturated fat ratio, red and processed meats, and alcohol [52]. Similarly, the DASH score evaluates consumption of fruits, vegetables, nuts and legumes, whole grains, low-fat dairy, while penalizing high intake of sodium, red/processed meats, and sweetened beverages [20]. The HEI measures conformance to national dietary guidelines, comprising 13 components that assess both adequacy and moderation of different food groups [20].
The construction of a priori patterns follows a standardized protocol: (1) select target dietary pattern based on research question; (2) define dietary components and scoring criteria based on established methodology; (3) collect dietary intake data using appropriate assessment tools; (4) calculate component scores based on intake levels; (5) sum component scores to create a composite index; and (6) categorize participants into quantiles of adherence for analysis. The main advantage of a priori methods is their ability to provide standardized, comparable measures of diet quality across different populations. However, they may not capture culturally specific or emerging dietary patterns relevant to particular study populations [52] [20].
A Posteriori Dietary Pattern Analysis
A posteriori dietary pattern analysis uses data-driven statistical methods to identify habitual dietary patterns within a specific population without predefined hypotheses. This exploratory approach allows for the discovery of population-specific eating behaviors and emerging patterns that may not be captured by existing dietary indices. The most common statistical techniques include principal component analysis (PCA), factor analysis, and partial least-squares (PLS) regression [52] [54].
Principal component analysis (PCA) is the most widely used method, reducing multiple correlated food variables into a smaller number of uncorrelated patterns (components) that explain maximum variance in the dietary data. The analytical process involves: (1) collapsing individual food items into biologically meaningful food groups; (2) standardizing consumption values (typically as servings per day or grams per 1000 kcal); (3) applying factor analysis with varimax or orthogonal rotation to simplify factor structure; (4) determining the number of patterns to retain based on eigenvalues (>1.0), scree plot examination, and interpretability; (5) interpreting patterns based on factor loadings (typically >|0.25| or >|0.30|); and (6) calculating pattern scores for each participant by summing consumption of food groups weighted by their factor loadings [55] [54].
Partial least-squares (PLS) regression represents a more recent advancement that derives dietary patterns that maximally explain the covariance between food intake and specific response variables (e.g., biomarkers or disease outcomes) [52]. This method is particularly valuable when the research objective is to identify dietary patterns most relevant to a specific health outcome. Regardless of the specific technique, a posteriori methods provide insights into population-specific eating behaviors but are limited by reduced comparability across studies and sensitivity to methodological choices in food grouping and factor extraction [3].
Comparative Analysis of Methodological Approaches
Table 1: Comparison of A Priori and A Posteriori Dietary Pattern Analysis Methods
| Characteristic | A Priori Approach | A Posteriori Approach |
|---|---|---|
| Theoretical Basis | Hypothesis-driven based on existing knowledge | Exploratory, data-driven |
| Common Methods | Dietary indices (MED, DASH, HEI) | PCA, factor analysis, PLS, cluster analysis |
| Output | Predefined score measuring adherence | Empirically derived patterns specific to population |
| Comparability | High across studies | Limited, population-specific |
| Interpretability | Straightforward, based on predefined criteria | Requires interpretation of factor loadings |
| Key Advantages | Standardized, hypothesis-testing | Discovers emerging patterns, population-specific |
| Key Limitations | May miss culturally specific patterns | Reduced comparability, method-sensitive |
Case Studies in Women of Childbearing Age
Dietary Pattern Tracking from Pregnancy to Post-Pregnancy
The GUSTO (Growing Up in Singapore Toward healthy Outcomes) study provides a compelling longitudinal case study examining dietary pattern stability in women from pregnancy to 6 years post-pregnancy [55]. This research employed distinct dietary assessment methods at each time point: a multiple-pass 24-hour recall during pregnancy (26-28 weeks' gestation) and a 133-item semi-quantitative food frequency questionnaire (FFQ) at 6 years post-pregnancy. The researchers applied principal component analysis (PCA) separately at each time point to identify dietary patterns.
The analysis revealed two consistent patterns at both time points: 'Fruits, Vegetables and Legumes' (FVL) and 'Seafood, Noodle, Soup' (SNS). However, tracking analysis demonstrated poor stability of these patterns over time, with low correlation for dietary pattern z-scores (r: 0.2 and 0.3, respectively) and modest agreement in tertile assignment. Notably, an 'unhealthy' pattern characterized by processed foods, sweets, and fried items was only observed at 6 years post-pregnancy. The study employed multiple logistic regression to identify sociodemographic and lifestyle factors influencing dietary pattern adherence, finding that women with higher educational attainment and healthier lifestyle behaviors were more likely to maintain or increase adherence to the FVL pattern [55].
This case study highlights several methodological considerations for longitudinal dietary pattern research. The use of different dietary assessment tools at each time point presents interpretation challenges, as true dietary changes must be distinguished from measurement artifact. Additionally, the modest tracking correlations underscore that women's dietary habits can change substantially during the transition from pregnancy to mid-childhood, suggesting critical windows for nutritional interventions.
Socio-Demographic Influences on Pre-Pregnancy Dietary Patterns
The ProcriAr cohort study conducted in São Paulo, Brazil, offers insights into socio-demographic determinants of dietary patterns in women of childbearing age [54]. This research utilized a validated 110-item food frequency questionnaire (FFQ) to assess pre-pregnancy dietary intake over the previous 12 months. Through principal component factor analysis with varimax rotation, the researchers identified four distinct dietary patterns: (1) 'Lentils, whole grains and soups'; (2) 'Snacks, sandwiches, sweets and soft drinks'; (3) 'Seasoned vegetables and lean meats'; and (4) 'Sweetened juices, bread and butter, rice and beans'.
Multiple linear regression models revealed significant associations between socio-demographic characteristics and pattern adherence. The 'Lentils, whole grains and soups' pattern was positively associated with maternal age, non-smoking status, and being born in the South, North, or Midwest of Brazil. The 'Snacks, sandwiches, sweets and soft drinks' pattern was positively associated with higher maternal education but negatively associated with age, lack of formal employment, and Northeast region birth. The 'Seasoned vegetables and lean meats' pattern was positively associated with higher maternal education, while the 'Sweetened juices, bread and butter, rice and beans' pattern was positively associated with unemployment and negatively associated with maternal overweight/obesity [54].
This case study demonstrates the substantial influence of socio-demographic factors on dietary patterns in women of childbearing age. The findings highlight the importance of considering cultural, educational, and economic factors when designing nutritional interventions for this population. Furthermore, the identification of a traditional Brazilian pattern ('Sweetened juices, bread and butter, rice and beans') illustrates how a posteriori methods can capture culturally specific eating patterns that might be overlooked by standard a priori indices.
Association Between Dietary Patterns and Health Outcomes
Research examining the relationship between dietary patterns and health outcomes in women of childbearing age has yielded important insights for clinical and public health practice. A comprehensive review of the role of diet in women of childbearing age synthesized evidence from recent reviews, cohort studies, and clinical trials, highlighting the profound impact of nutrition on menstrual, metabolic, cardiovascular, skeletal, and reproductive outcomes [53].
The evidence consistently links Mediterranean-style eating patterns with improved metabolic health, insulin sensitivity, in vitro fertilization (IVF) success rates, and reduced risk of gestational diabetes. Conversely, high consumption of ultra-processed foods is associated with poorer diet quality, increased inflammation, adverse pregnancy outcomes, and potential reproductive impairment. The review emphasizes priority nutrients for this population, including iron, folate, calcium, vitamin D, zinc, vitamin B12, and long-chain omega-3 fatty acids (DHA), with supplementation recommended when dietary intake is inadequate [53].
This accumulating evidence underscores the importance of dietary pattern analysis for developing targeted nutritional recommendations for women of childbearing age. The findings support a shift toward promoting overall dietary patterns rather than focusing exclusively on individual nutrients, providing a more holistic approach to supporting maternal and offspring health.
Technical Protocols and Methodological Frameworks
Experimental Workflow for Dietary Pattern Analysis
The following diagram illustrates the comprehensive methodological workflow for conducting both a priori and a posteriori dietary pattern analysis in research populations:
Dietary Assessment Methodologies
Table 2: Dietary Assessment Tools for Pattern Analysis in Research Settings
| Assessment Method | Key Features | Applications | Strengths | Limitations |
|---|---|---|---|---|
| Food Frequency Questionnaire (FFQ) | Fixed food list with frequency response options; can be quantitative or semi-quantitative | Large epidemiological studies; assessment of usual intake over extended periods | Efficient for large samples; captures seasonal variation; lower participant burden | Memory dependent; limited detail on specific eating occasions; culturally specific |
| 24-Hour Dietary Recall | Structured interview assessing all foods/beverages consumed previous day; multiple-pass method enhances accuracy | Detailed intake assessment; validation studies; can estimate within-person variation | Minimal memory bias; quantitative data on specific days; high detail | High participant and researcher burden; single day may not represent usual intake |
| Dietary Records/Diaries | Prospective recording of all foods/beverages as consumed; typically 3-7 days | Metabolic studies; validation research; detailed pattern analysis | Minimizes memory bias; highly detailed data; accurate portion size assessment | High participant burden; may alter usual eating habits; literacy requirement |
Statistical Analysis Framework for Dietary Pattern Derivation
The statistical derivation of a posteriori dietary patterns involves a multi-step process with critical decision points at each stage. For principal component analysis (PCA), the key steps include: (1) Food Grouping: Collapsing individual food items into biologically meaningful groups based on nutrient profile and culinary use (e.g., "whole grains," "processed meats," "leafy green vegetables"); (2) Standardization: Adjusting intake values for total energy intake using the residual method or calculating consumption as servings per 1000 kcal; (3) Factor Extraction: Applying PCA to the correlation matrix of food groups and determining the number of patterns to retain based on eigenvalues (>1.0), scree plot inflection point, and interpretability; (4) Rotation: Using orthogonal (varimax) or oblique rotation to simplify factor structure and enhance interpretability; and (5) Score Calculation: Deriving pattern scores for each participant by summing standardized consumption of food groups weighted by their factor loadings [55] [54].
For a priori pattern analysis, the statistical framework involves: (1) Index Selection: Choosing an appropriate dietary index (e.g., aMED, DASH, HEI) based on research question; (2) Component Definition: Defining food components and scoring criteria according to established methodologies; (3) Intake Calculation: Computing daily intake of each food component; (4) Scoring: Assigning points for each component based on predefined cut-offs (often population-specific quintiles or recommended intake levels); and (5) Index Calculation: Summing component scores to create a composite index for each participant [52] [20].
Both approaches typically use multivariable regression models (linear, logistic, or Cox proportional hazards) to examine associations between dietary pattern scores and health outcomes, adjusting for potential confounders such as age, energy intake, socioeconomic status, physical activity, and other relevant covariates.
Research Reagent Solutions: Methodological Tools
Table 3: Essential Methodological Tools for Dietary Pattern Analysis
| Tool Category | Specific Tools/Software | Application in Dietary Analysis | Technical Specifications |
|---|---|---|---|
| Dietary Assessment Platforms | NDSR (Nutrition Data System for Research), GloboDiet, ASA24 | Standardized dietary data collection and nutrient analysis | Automated multiple-pass 24-hour recall; standardized nutrient databases; multi-language capabilities |
| Statistical Analysis Software | R, SAS, STATA, SPSS, Python | Data cleaning, dietary pattern derivation, statistical modeling | PCA procedures; factor analysis; regression modeling; data visualization |
| Dietary Pattern Packages | R 'factoextra', 'psych', 'FactoMineR' packages | Specialized multivariate analysis for dietary pattern derivation | Automated scree plots; factor loading extraction; dimension reduction visualization |
| Dietary Index Calculators | HEI, MED, DASH scoring algorithms | Automated calculation of a priori dietary pattern scores | Standardized scoring based on USDA/established criteria; handling of missing data |
| Food Composition Databases | USDA FoodData Central, FoodCompl, country-specific FCDB | Conversion of food consumption to nutrient intake | Comprehensive nutrient profiles; recipe calculation algorithms; bioavailability factors |
Data Visualization Approaches for Dietary Pattern Research
Effective data visualization is essential for communicating complex dietary pattern analysis results. The following diagram illustrates the relationship between different dietary pattern methods and their applications in nutritional epidemiology:
Visualization Color Palette Guidelines
Based on data visualization best practices [56] [57], the following color guidelines are recommended for dietary pattern research visualizations:
- Categorical/Qualitative Palettes: Use distinct hues with varying lightness for different dietary patterns or food groups (maximum 10 colors). Ensure colorblind accessibility by testing contrast and avoiding red-green combinations.
- Sequential Palettes: Use single-hue or multi-hue gradients from light to dark for visualizing continuous variables (e.g., adherence scores, nutrient densities).
- Diverging Palettes: Use two contrasting hues with a light neutral midpoint for visualizing deviations from reference values (e.g., compared to population mean).
These visualization strategies enhance the interpretability of complex dietary pattern data and facilitate effective communication of research findings to scientific audiences and stakeholders.
Dietary pattern analysis provides powerful methodological approaches for understanding the complex relationship between diet and health in specific populations. The application of both a priori and a posteriori methods to women of childbearing age has yielded critical insights into the dietary determinants of maternal and offspring health. The case studies examined in this technical guide demonstrate that dietary patterns in this population are influenced by socio-demographic factors and track modestly over time, with important implications for nutritional interventions.
Future research directions should include: (1) standardization of dietary pattern methodologies to enhance cross-study comparability; (2) development of culturally specific a priori indices that capture relevant traditional eating patterns; (3) integration of omics technologies to elucidate biological mechanisms linking dietary patterns to health outcomes; and (4) application of advanced statistical methods such as reduced rank regression and partial least squares to identify pathways between diet and disease. As dietary pattern methodology continues to evolve, its application to women of childbearing age will remain essential for advancing maternal nutrition science and developing evidence-based nutritional recommendations for this critical population.
Navigating Analytical Challenges and Optimizing Method Selection
Common Pitfalls in Index Construction and Pattern Derivation
In nutritional epidemiology, the analysis of dietary patterns has emerged as a fundamental approach to understanding the complex relationship between diet and health. These analyses are primarily categorized into two distinct methodologies: a priori (investigator-driven) and a posteriori (data-driven) approaches [15] [7]. The a priori method involves defining dietary patterns based on existing nutritional knowledge, guidelines, or hypotheses, resulting in dietary quality scores or indices that measure adherence to pre-defined healthy eating patterns [7]. In contrast, the a posteriori approach uses multivariate statistical techniques to derive dietary patterns empirically from dietary intake data without pre-conceived hypotheses, identifying common eating habits within a study population [15] [26]. This technical guide examines the common pitfalls in constructing both types of dietary patterns within the broader context of nutritional epidemiology research, providing methodological guidance for researchers, scientists, and drug development professionals engaged in diet-disease investigations.
Fundamental Concepts and Definitions
A Priori Dietary Patterns
A priori dietary patterns are conceptually defined based on current nutrition science and evidence-based diet-health relationships [15]. These indices aggregate individually quantified dietary components considered important for health promotion into an overall measure of dietary quality. Well-established examples include the Healthy Eating Index (HEI), Mediterranean Diet Score (MedDietScore), Dietary Approaches to Stop Hypertension (DASH) score, and various Diet Quality Index (DQI) versions [15] [7]. These indices are constructed to reflect risk gradients for major diet-related diseases and are grounded in prior nutritional knowledge rather than being derived exclusively from the dataset under study.
A Posteriori Dietary Patterns
A posteriori dietary patterns are derived through statistical methods using dietary intake data from the population under investigation [15]. These exploratory techniques aggregate intake variables into factors that reveal underlying consumption patterns within a specific population. Common methods include principal component analysis (PCA), factor analysis (FA), and cluster analysis [7] [58]. Unlike a priori patterns, a posteriori patterns are not necessarily based on nutritional knowledge about what constitutes a healthy diet but instead represent actual eating patterns identified through data reduction techniques.
Comparative Characteristics
The fundamental differences between these approaches have significant methodological implications. A priori patterns allow for consistent application across different populations but may not capture culturally-specific eating behaviors. A posteriori patterns are population-specific but not necessarily health-oriented and may not be reproducible across different study populations [15] [26]. This dichotomy establishes the foundation for understanding the distinct pitfalls associated with each method.
Pitfalls in A Priori Index Construction
Theoretical Framework Limitations
The construction of a priori indices often suffers from theoretical shortcomings that compromise their validity. Many indices lack a clearly articulated theoretical framework regarding index purpose and structure, leading to inconsistent interpretation of nutritional guidelines across research teams [15]. This ambiguity introduces subjectivity in how dietary components are selected and weighted. Furthermore, index accuracy is inherently limited by the current state of dietary knowledge regarding diet-health relationships, creating gaps between index components and emerging nutritional science [15]. The Organisation for Economic Co-operation and Development (OECD) handbook outlines key issues in index construction that are frequently overlooked, including inadequate consideration of purpose, structure, and theoretical foundations [15].
Indicator Selection and Normalization Issues
The process of selecting and normalizing indicators presents multiple pitfalls in a priori index development. Table 1 summarizes the primary pitfalls in a priori index construction:
Table 1: Common Pitfalls in A Priori Dietary Index Construction
| Construction Phase | Pitfall | Consequence | Recommended Solution |
|---|---|---|---|
| Theoretical Framework | Unclear theoretical foundation | Compromised validity and interpretation | Apply OECD handbook criteria for index purpose and structure [15] |
| Indicator Selection | Subjectively determined components | Limited capture of overall dietary patterns | Use evidence-based component selection with documented rationale |
| Normalization | Inconsistent scaling procedures | Reduced comparability across studies | Standardize cutoff points based on dietary recommendations |
| Valuation Functions | Arbitrary scoring systems | Questionable construct validity | Implement validated valuation functions aligned with biological effects |
| Aggregation | Inappropriate weighting of components | Misrepresentation of dietary quality importance | Use weighting based on established diet-disease relationships |
Indicator selection frequently reflects researcher subjectivity rather than evidence-based rationale, focusing only on selected aspects of diet while ignoring correlations between dietary components [15] [7]. Normalization methods, including scaling procedures and cutoff points, vary considerably between indices, reducing comparability across studies. Additionally, the use of arbitrary valuation functions without biological justification questions the construct validity of many indices [15].
Aggregation and Weighting Challenges
The aggregation of individual components into a composite score introduces significant methodological challenges. Many indices employ simple summation without theoretical justification for weighting schemes, potentially misrepresenting the relative importance of different dietary components [15]. This approach assumes all components contribute equally to overall dietary quality, despite varying effect sizes on health outcomes. Furthermore, comprehensive dietary scores often obscure specific information about multiple foods, leading to unclear interpretation of intermediate scores where individuals with similar total scores may have substantially different nutritional compositions [7].
Pitfalls in A Posteriori Pattern Derivation
Methodological Instability in Pattern Extraction
A posteriori dietary pattern derivation encounters several instability issues throughout the analytical process. The inherent subjectivity in decisions regarding food grouping before analysis significantly influences resulting patterns, as different grouping schemes can yield substantially different outcomes [7]. The determination of how many patterns to retain often relies on subjective criteria like eigenvalues greater than one or scree plot interpretation, without consistent application across studies [7] [58]. Additionally, pattern stability is highly sensitive to sample size, with smaller samples producing less reproducible patterns, particularly when using principal component analysis (PCA) compared to confirmatory factor analysis (CFA) [58].
Interpretation and Naming Biases
The interpretation and labeling of derived patterns introduces significant researcher bias. The naming of patterns based on factor loadings often reflects researcher preconceptions rather than objective criteria, potentially misrepresenting the underlying dietary constructs [7]. This subjectivity extends to decisions about which food groups to emphasize in pattern characterization, with inconsistent cutoff points for meaningful factor loadings across studies. Furthermore, the rotational methods applied to simplify factor structure (e.g., varimax rotation) represent another source of subjective decision-making that influences final pattern configuration [7].
Validation and Reproducibility Limitations
A posteriori patterns face substantial challenges in validation and reproducibility. Population-specific derivation limits generalizability across different demographic, cultural, or geographic groups, restricting external validity [15]. Additionally, the data-driven nature of these patterns means they are not necessarily health-oriented, as they represent actual eating habits within a population without regard to health outcomes [15]. Table 2 summarizes key validation challenges specific to a posteriori methods:
Table 2: Validation Challenges in A Posteriori Pattern Derivation
| Challenge Category | Specific Issue | Impact on Validity |
|---|---|---|
| Methodological Stability | Sample size sensitivity | Reduced reproducibility in small samples [58] |
| Food grouping subjectivity | Inconsistent pattern extraction | |
| Retention criteria variability | Non-comparable patterns across studies | |
| Interpretative Consistency | Naming bias | Subjectivity in pattern characterization |
| Factor loading interpretation | Emphasis on different dietary aspects | |
| Generalizability | Population specificity | Limited cross-cultural application [15] |
| Temporal instability | Patterns not consistent over time |
Comparative Methodological Considerations
Predictive Performance Comparisons
Research comparing the predictive performance of a priori and a posteriori approaches reveals important considerations for method selection. Studies examining acute coronary syndrome (ACS) and ischemic stroke prediction found similar classification accuracy between both approaches across multiple machine learning algorithms [26]. For ACS prediction, C-statistics ranged from 0.587 to 0.807 for a priori patterns and 0.583 to 0.827 for a posteriori patterns, indicating comparable discriminatory capacity [26]. These findings suggest that choice of method should depend on the specific research application rather than assumed superiority of either approach.
Analytical Workflows
The fundamental differences between a priori and a posteriori approaches are visualized in their distinct analytical workflows:
Diagram 1: Methodological workflows of dietary pattern approaches
Contextual Method Selection
The choice between a priori and a posteriori methods should be guided by specific research objectives, as each approach offers distinct advantages for different investigative contexts. A priori methods are preferable when testing hypotheses about adherence to established dietary guidelines or when comparing results across diverse populations [15] [7]. A posteriori methods are more appropriate for exploring population-specific eating patterns without pre-conceived hypotheses or for identifying novel dietary behaviors in understudied populations [15] [26]. Hybrid approaches that combine elements of both methodologies may offer complementary insights, though they introduce additional analytical complexity.
Advanced Methodological Approaches
Emerging Statistical Techniques
Recent methodological advances have introduced several emerging techniques for dietary pattern analysis that address limitations of traditional approaches. The finite mixture model (FMM) represents a model-based clustering method that offers probabilistic assignment to dietary patterns [7]. Treelet transform (TT) combines principal component analysis and clustering algorithms in a unified process, potentially enhancing pattern stability [7]. Compositional data analysis (CODA) addresses the compositional nature of dietary data by transforming intake into log-ratios, properly accounting for the constant-sum constraint inherent in dietary intake [7]. These emerging methods present opportunities to overcome specific pitfalls but require further validation regarding reproducibility and predictive performance.
Machine Learning Applications
Machine learning algorithms offer promising approaches for dietary pattern analysis, potentially overcoming limitations of traditional statistical methods. Studies have demonstrated successful application of multiple classification algorithms including naïve Bayes, decision trees, artificial neural networks, and support vector machines for diet-disease prediction [26]. These techniques can enhance predictive performance and handle complex nonlinear relationships between dietary components and health outcomes. However, they introduce new challenges regarding interpretability, overfitting, and computational complexity that require careful methodological consideration.
Methodological Integration Framework
The integration of multiple methodological approaches within a coherent framework can mitigate individual method limitations:
Diagram 2: Integrated framework for dietary pattern methodology
Experimental Protocols and Validation Standards
Standardized Validation Protocol
Robust validation of dietary patterns requires a systematic approach addressing multiple measurement properties. The following protocol outlines key validation steps:
- Content Validity Assessment: Evaluate theoretical foundation and component selection through expert review and alignment with current nutritional science [15].
- Construct Validity Testing: Examine relationships with biomarkers, nutrient intakes, and health outcomes to verify the pattern measures intended constructs [15] [26].
- Reproducibility Analysis: Assess stability across different population subgroups, time periods, and methodological variations [58].
- Predictive Performance Evaluation: Test ability to predict relevant health outcomes using appropriate statistical measures (e.g., C-statistics, risk ratios) [26].
- Comparative Validation: Compare performance against established dietary patterns and assessment methods [26].
Research Reagent Solutions
Table 3 presents essential methodological tools for dietary pattern research:
Table 3: Research Reagent Solutions for Dietary Pattern Analysis
| Methodological Tool | Function | Implementation Considerations |
|---|---|---|
| Dietary Assessment Platforms | Data collection | Choice of FFQ, 24-hour recall, or food records based on research objectives |
| Statistical Software (R, SAS, Stata) | Pattern derivation | Availability of specialized packages for PCA, FA, CFA, and emerging methods |
| Dietary Pattern Indices | A priori assessment | Selection of appropriate index (HEI, DASH, MED) based on research question |
| Machine Learning Libraries | Advanced pattern recognition | Application of classification algorithms for enhanced prediction |
| Compositional Data Analysis Tools | Proper handling of compositional data | Transformation of dietary data to address constant-sum constraint |
Reporting Standards Framework
Comprehensive reporting of methodological details is essential for interpreting and comparing dietary pattern studies. The following elements should be explicitly documented:
- Theoretical Rationale: Clear description of the theoretical framework guiding index construction or pattern interpretation [15].
- Component Selection: Justification for inclusion/exclusion of specific dietary components with evidence-based rationale [15].
- Analytical Decisions: Documentation of all subjective decisions including food grouping, factor retention criteria, rotational methods, and scoring approaches [7].
- Validation Procedures: Detailed description of internal and external validation methods with appropriate statistical measures [26].
- Limitations: Acknowledgment of methodological constraints and potential biases introduced by analytical choices [15] [7].
The construction and derivation of dietary patterns through both a priori and a posteriori approaches present distinct methodological challenges that can significantly impact research validity and reproducibility. A priori indices frequently suffer from theoretical framework limitations, subjective component selection, and arbitrary aggregation methods, while a posteriori patterns face issues of methodological instability, interpretive bias, and limited generalizability. Rather than asserting superiority of either approach, researchers should select methods based on specific research questions, recognizing that both can achieve comparable predictive performance when appropriately implemented [26]. Future methodological development should focus on integrating emerging statistical techniques, establishing standardized validation protocols, and improving reporting standards to enhance the rigor and translational impact of dietary pattern research in nutritional epidemiology and drug development.
Addressing Subjectivity in Food Grouping and Pattern Naming
Dietary pattern analysis has revolutionized nutritional epidemiology by shifting the focus from individual nutrients to the complex combinations of foods that constitute a whole diet [5]. This approach more accurately reflects real-world eating habits, where nutrients and foods are consumed in synergy, and accounts for the intricate interactions that single-food analyses often miss [11] [5]. However, this methodological advancement introduces significant challenges in standardizing food grouping and pattern naming practices. The core of this challenge lies in the inherent subjectivity that researchers face at multiple stages of analysis, from initial data preprocessing to the final interpretation and labeling of derived patterns [11] [7].
The issue of subjectivity is framed within the fundamental dichotomy between a priori (hypothesis-driven) and a posteriori (data-driven) analytical approaches [11] [10]. A priori methods use predefined scores or indices to assess adherence to an "ideal" diet based on current nutritional knowledge, such as the Mediterranean Diet Score (MDS) or Healthy Eating Index (HEI) [11] [7]. In contrast, a posteriori methods, including Principal Component Analysis (PCA) and cluster analysis, use statistical techniques to identify eating patterns that exist within the study population itself, without predetermined hypotheses [11] [10]. Both pathways require researchers to make numerous subjective decisions that can significantly influence the final results and their interpretation [11] [59].
This technical guide provides a comprehensive framework for identifying, quantifying, and mitigating subjectivity throughout the dietary pattern analysis pipeline. By establishing standardized protocols and leveraging emerging methodologies, researchers can enhance the reproducibility, validity, and cross-population comparability of their findings in nutritional epidemiology and drug development research.
Foundational Concepts: A Priori vs. A Posteriori Approaches
Understanding the distinct methodologies and inherent limitations of a priori and a posteriori approaches is essential for addressing subjectivity in dietary pattern research. The table below summarizes the core characteristics, strengths, and limitations of each approach.
Table 1: Comparison of A Priori and A Posteriori Dietary Pattern Approaches
| Feature | A Priori (Hypothesis-Driven) | A Posteriori (Data-Driven) |
|---|---|---|
| Definition | Predefined scores based on existing dietary guidelines or hypotheses [11] [7] | Patterns derived statistically from population dietary intake data [11] [10] |
| Primary Methods | Dietary indices/scores (e.g., HEI, MDS, DASH) [5] [7] | Principal Component Analysis (PCA), Factor Analysis, Cluster Analysis [11] [7] |
| Key Rationale | Measures adherence to "ideal" diet linked to health outcomes [11] | Describes existing dietary patterns in a specific population [10] |
| Inherent Subjectivity | Selection of components, cut-offs, and scoring systems [11] [7] | Decisions on food aggregation, number of factors, factor rotation, and pattern naming [11] [7] |
| Strengths | Grounded in nutritional evidence; allows cross-study comparison [7] | Reflects population's actual dietary habits; identifies unknown patterns [10] |
| Limitations | May not capture culturally-specific eating patterns [11] | Patterns may not be associated with health outcomes; limited reproducibility across populations [11] |
A crucial challenge with a priori scores is their transferability across different populations. For instance, the Alternative Healthy Eating Index (AHEI) was developed in the U.S. context, and when applied in Australia, most participants received the top score for trans-fatty acid intake because baseline intakes were much lower than in the U.S. [11]. This results in a compressed score distribution that fails to discriminate effectively between individuals. Similarly, the original Mediterranean Diet Score (MDS) bases its scoring on median intakes within the study population, which can be problematic—if overall intake of Mediterranean diet components is low in a population, even the highest-scoring individuals may not reach levels seen in traditional Mediterranean diets and thus may not show expected health associations [11].
For a posteriori methods, subjectivity emerges prominently during statistical implementation. In PCA, researchers must decide on the number of factors to retain, the rotation method, and the interpretation of factor loadings [7]. These decisions can dramatically alter the resulting patterns. Furthermore, the naming of derived patterns often relies on researcher interpretation rather than standardized criteria, potentially leading to misleading labels. For example, a "traditional" dietary pattern identified in Iran differs substantially in actual food composition from a similarly named pattern in Australia, reflecting quite different foods and showing different associations with health outcomes [11].
Methodological Workflow and Decision Points
The process of deriving dietary patterns involves multiple sequential steps, each introducing specific subjectivity challenges that researchers must navigate systematically. The diagram below maps this workflow, highlighting critical decision points where subjective judgments occur.
Food Grouping and Aggregation Protocols
Before any pattern analysis, raw dietary data must be aggregated into meaningful food groups—a step that introduces significant subjectivity. The level of aggregation profoundly impacts subsequent pattern derivation. Research by Bountziouka et al. demonstrated that using food groups instead of individual food items explained more variation in dietary intake (43-46% versus 23-25%) and produced more stable patterns on repeat testing [10].
Table 2: Standardized Food Grouping Protocol to Minimize Subjectivity
| Grouping Decision | Subjectivity Risk | Recommended Protocol |
|---|---|---|
| Granularity Level | High - Varying levels of detail obscure comparisons | Use standardized nutrient-based or cultural-based grouping systems; document all decisions [59] |
| Mixed Dishes | High - Inconsistent assignment across studies | Develop predefined rules for decomposing mixed dishes into ingredients; use recipe databases |
| Cultural Adaptation | Medium - Ethnocentric grouping biases | Involve cultural nutrition experts; validate grouping relevance with local populations |
| Classification Basis | Medium - Different rationales yield different groups | Explicitly state classification basis (nutritional, culinary, processing level) and justify choice [59] |
Naturalistic categorization research reveals that individuals primarily group foods based on perceived processing level ("grown or manufactured") rather than macronutrient content [59]. This discrepancy between researcher-defined categories (e.g., high-fat, low-sugar) and natural consumer categorization highlights a fundamental subjectivity challenge in how we conceptualize and group foods for analysis.
Pattern Naming Conventions and Standards
The naming of derived dietary patterns represents perhaps the most visibly subjective aspect of the analysis process. Studies have shown that different researchers might assign different names to identical patterns based on their interpretation, disciplinary background, or cultural context [11].
To address this, we propose the following standardized naming protocol:
- Component-Driven Naming: Base names primarily on the highest-loading food groups (>|0.25|) in descending order of contribution [11].
- Avoid Value-Laden Terms: Replace subjective terms like "healthy" or "unhealthy" with neutral descriptors based on actual food composition.
- Cultural Context Specification: Always reference the population context (e.g., "Traditional Southern Chinese Pattern" rather than simply "Traditional Pattern") [11].
- Quantitative Justification: Document the factor loadings and variance explained for each named pattern to support the chosen nomenclature.
For example, rather than naming a pattern "Western Diet," a more objective description would be "High Red Meat, Refined Grain, and Processed Food Pattern," explicitly referencing the specific foods with the highest factor loadings that define the pattern.
Emerging Methods and Advanced Statistical Approaches
Several emerging statistical methods offer promising approaches to reduce subjectivity in dietary pattern analysis while providing enhanced capabilities for handling complex dietary data.
Treelet Transform (TT)
Treelet Transform (TT) is a dimension-reduction technique that combines features of both PCA and cluster analysis in a one-step process [11] [5]. Unlike PCA, where each factor involves all original variables, TT produces factors with naturally grouped variables that are easier to interpret [11]. In a study using data from over 300,000 women in the European Prospective Investigation into Cancer and Nutrition (EPIC), TT identified one pattern rich in nutrients from animal foods and another loading on nutrients from fruits, vegetables, and cereals, with the latter associated with reduced breast cancer risk [11]. Users must subjectively select a cut-level for the cluster tree, though cross-validation techniques can identify the optimal level objectively [11].
Reduced Rank Regression (RRR)
Reduced Rank Regression (RRR) is a hybrid approach that explains the relationship between diet and health via intermediate response variables such as biomarkers or nutrient densities [5]. In a study comparing PCA and RRR for identifying patterns associated with diabetes, the PCA-derived "modern high-wheat" and "traditional southern" patterns showed significant associations only in unadjusted models, while the RRR-identified pattern (which combined elements of both PCA patterns) remained significantly associated with diabetes even after adjustment [11]. This suggests RRR may identify patterns more directly relevant to specific disease pathways.
Compositional Data Analysis (CODA)
Compositional Data Analysis (CODA) addresses the inherent compositional nature of dietary data—where components exist in a constant-sum constraint—by transforming intake data into log-ratios [7]. This approach properly accounts for the relative nature of dietary intake, where consuming more of one food necessarily means consuming less of others, thereby reducing artifacts introduced by traditional statistical methods not designed for compositional data [7].
Gaussian Mixed Models (GMM) for Cluster Analysis
In comparative methodological studies, Gaussian Mixed Models (GMM)—a model-based clustering approach—have demonstrated superior performance over traditional k-means and Ward's method clustering algorithms, particularly in simulated data [11]. This suggests GMM may offer more objective and reproducible clustering solutions for identifying dietary patterns in heterogeneous populations.
Experimental Protocols for Methodological Validation
Rigorous experimental protocols are essential for validating dietary pattern methodologies and quantifying their subjectivity. Below we outline standardized protocols for assessing key methodological properties.
Protocol for Testing Short-Term Stability
Purpose: To evaluate the test-retest reliability of derived dietary patterns over a short interval [10].
Materials and Equipment:
- Validated Food Frequency Questionnaire (FFQ)
- Statistical software (R, SAS, or STATA)
- Computing hardware capable of running multivariate statistics
Procedure:
- Administer the dietary assessment instrument (e.g., 76-item FFQ) to participants at Time 1 (n=500 recommended) [10]
- After a 15-day interval, readminister the same instrument to the same participants (Time 2) [10]
- Apply the same dietary pattern method (a priori or a posteriori) separately to both datasets
- For a priori patterns: Calculate correlation coefficients (Kendall's tau-b) between Time 1 and Time 2 scores [10]
- For a posteriori patterns: Compare factor structures using congruence coefficients or Procrustes rotation
- Compare variance explained by patterns at both time points
Interpretation: High stability is indicated by correlation coefficients >0.6 for a priori scores and similar factor structures with comparable explained variance for a posteriori patterns [10].
Protocol for Cross-Population Validation
Purpose: To assess the transferability of dietary patterns across different populations or cultural contexts.
Materials and Equipment:
- Dietary intake data from at least two distinct populations
- Standardized food grouping system
- Statistical software for multivariate analysis
Procedure:
- Derive dietary patterns in Population A using standard methods
- Apply the patterns from Population A to Population B and assess fit
- Derive patterns independently in Population B and compare with those from Population A
- Use confirmatory factor analysis to test pattern similarity
- Assess whether similar patterns show consistent associations with health outcomes in both populations
Interpretation: Successful cross-population validation is indicated by similar pattern structures and consistent direction of health associations, though absolute factor loadings may differ.
Table 3: Essential Resources for Dietary Pattern Analysis with Subjectivity Mitigation
| Tool Category | Specific Tools/Software | Application in Addressing Subjectivity |
|---|---|---|
| Statistical Software | R (factoextra, FactoMineR, compositions), SAS (PROC FACTOR, PROC CLUSTER), STATA |
Implements multiple methods for comparison; enables replication and sensitivity analyses [7] |
| Dietary Assessment Platforms | ASA24, GloboDiet, Food Frequency Questionnaire platforms | Standardizes initial data collection, reducing measurement subjectivity |
| Food Composition & Grouping Tools | FoodPatterns, FOODCASE, USDA Food Group databases | Provides standardized food grouping systems to minimize arbitrary categorization |
| Validation & Sensitivity Packages | R sensitivity, boot, mice |
Performs bootstrap validation, multiple imputation, and sensitivity analyses for decision points |
| Cultural Adaptation Frameworks | Cultural Food Pattern Atlas, TRANS-NUT classification | Provides systematic approaches for culturally appropriate food grouping |
Addressing subjectivity in food grouping and pattern naming requires a multifaceted approach combining methodological rigor, standardized protocols, and emerging statistical techniques. Key recommendations include: (1) adopting standardized food grouping systems with explicit documentation of all decisions; (2) implementing objective pattern naming conventions based on factor loadings rather than researcher interpretation; (3) utilizing emerging methods like Treelet Transform and Compositional Data Analysis where appropriate; and (4) systematically validating patterns through stability testing and cross-population comparison.
Future research should focus on developing automated food grouping algorithms, establishing international standards for pattern nomenclature, and further validating emerging methodologies across diverse populations. The integration of biological data, including metabolomic profiles and gut microbiome composition, offers promising avenues for grounding dietary patterns in objective biological measures rather than solely statistical constructs [5]. As dietary pattern analysis continues to evolve in nutritional epidemiology and drug development research, continued attention to methodological subjectivity will enhance the validity, reproducibility, and translational impact of this important analytical approach.
The Problem of Reproducibility and Standardization Across Populations
Reproducibility and standardization represent fundamental challenges in nutritional epidemiology, particularly in the analysis of dietary patterns. The ability to independently verify research findings and consistently apply methodologies across diverse populations is paramount for establishing reliable diet-disease relationships. Within the context of a priori and a posteriori dietary pattern analysis, these challenges manifest distinctly, affecting the translation of research into effective public health interventions and clinical applications.
Reproducibility in science refers to the ability to draw similar conclusions from replicate studies, while replication involves utilizing similar methods to collect new data and produce the same pattern of results [60]. In dietary pattern research, this translates to consistently identifying similar patterns and their health associations across different populations and study designs. The reproducibility crisis evident across scientific disciplines—where approximately 70% of scientists report being unable to reproduce others' studies, and 50% cannot reproduce their own work—has significant implications for nutritional science [60]. This crisis stems from multiple factors including inadequate experimental design, methodological variability, pressure to publish, and insufficient training in research integrity.
This technical guide examines the specific reproducibility challenges inherent in both a priori and a posteriori dietary pattern analyses, provides quantitative assessments of current methodologies, outlines standardized protocols, and proposes frameworks for enhancing cross-population comparability in nutritional research.
Methodological Foundations: A Priori vs. A Posteriori Dietary Patterns
Dietary pattern analysis represents a holistic approach to nutritional epidemiology that addresses the complex synergies between foods and nutrients. The two predominant methodologies—a priori and a posteriori analysis—differ fundamentally in their approach and face distinct reproducibility challenges.
A Priori Dietary Patterns
A priori dietary patterns are hypothesis-driven approaches based on predefined nutritional knowledge. These patterns use dietary indices that capture adherence to established healthy eating patterns, such as the Mediterranean diet or vegetarian diets [61] [26]. The MedDietScore, for instance, assesses adherence to the Mediterranean dietary pattern by evaluating consumption of vegetables, legumes, fruit, nuts, fish, wholegrains, the ratio of monounsaturated to saturated fat, and limited red and processed meat intake [61] [26].
Key characteristics of a priori methods include:
- Based on existing nutritional knowledge and hypotheses
- Predefined scoring systems or indices
- Theory-driven structure
- Designed for specific population comparisons
- Generally more reproducible across studies due to standardized definitions
A Posteriori Dietary Patterns
A posteriori dietary patterns are data-driven approaches derived empirically from dietary intake data using multivariate statistical techniques. The most common method is principal components analysis (PCA), which identifies intercorrelations among food items and groups them into patterns based on consumption habits [26]. Other techniques include factor analysis and cluster analysis.
Key characteristics of a posteriori methods include:
- Derived empirically from dietary intake data
- Use multivariate statistical techniques (PCA, factor analysis, cluster analysis)
- Specific to the population being studied
- Captures prevailing eating habits without predefined hypotheses
- Subject to greater variability due to methodological choices
Table 1: Comparison of A Priori and A Posteriori Dietary Pattern Methodologies
| Characteristic | A Priori Patterns | A Posteriori Patterns |
|---|---|---|
| Basis | Pre-existing knowledge | Empirical data |
| Method | Dietary indices/scores | Multivariate statistics |
| Examples | MedDietScore, Healthy Eating Index | Principal Components Analysis |
| Reproducibility | Higher (standardized definitions) | Lower (population-specific) |
| Cross-Population Comparison | More straightforward | Challenging |
| Hypothesis Testing | Confirmatory | Exploratory |
Quantitative Assessment of Reproducibility in Dietary Assessment Methods
Understanding the reproducibility of dietary assessment tools is crucial for interpreting diet-disease associations. Different assessment methods exhibit varying levels of reproducibility, which must be accounted for in study design and statistical analysis.
Reproducibility of 24-Hour Dietary Recalls
The UK Biobank study assessed the reproducibility of web-based 24-hour dietary assessments on up to five occasions in 211,050 participants [61]. The intra-class correlation coefficients (ICC) for macronutrients and food groups demonstrated moderate to substantial reproducibility when using the means of two 24-hour assessments:
Table 2: Reproducibility of Macronutrients Using 24-Hour Dietary Assessments (UK Biobank)
| Macronutrient | Intra-class Correlation Coefficient (ICC) |
|---|---|
| Alcohol | 0.63 |
| Protein | 0.57 |
| Total Fat | 0.49 |
| Carbohydrates | 0.47 |
| Saturated Fat | 0.44 |
| Polyunsaturated Fat | 0.36 |
Table 3: Reproducibility of Food Groups Using 24-Hour Dietary Assessments (UK Biobank)
| Food Group | Intra-class Correlation Coefficient (ICC) |
|---|---|
| Fruit | 0.68 |
| Vegetables | 0.55 |
| Cheese | 0.49 |
| Bread & Cereals | 0.43 |
| Meat | 0.41 |
| Fish | 0.18 |
The reproducibility was higher for specific dietary patterns, with vegetarian status showing excellent reproducibility (κ > 0.80) compared to the Mediterranean dietary pattern (ICC = 0.45) [61]. These findings highlight the substantial variability in reproducibility across different dietary components, with stable patterns like vegetarianism demonstrating higher consistency than quantitatively defined patterns.
Reproducibility of Food Frequency Questionnaires (FFQs)
The UK Biobank also evaluated the reproducibility of a short FFQ recorded at baseline (n = 502,655) and after 4 years (n = 20,346) [61]. The ICC for FFQ assessments varied from 0.66 for meat and fruit to 0.48 for bread and cereals, demonstrating generally moderate reproducibility over time.
The Harvard Food Frequency Questionnaire, developed over forty years of continued refinement, represents a standardized approach to semi-quantitative FFQ assessment [62]. This tool includes detailed nutrient database support and standardized processing protocols to enhance reproducibility across research settings.
Population vs. Individual Reproducibility
A critical distinction exists between the reproducibility of dietary patterns at the population level versus the individual level. The Doetinchem Cohort Study examined the stability and reproducibility of dietary patterns over three survey periods using cluster analysis [63]. While a "low-fiber bread pattern" and "high-fiber bread pattern" were identified consistently across all three surveys at the population level, only 41.8% of participants were consistently assigned to the same dietary pattern across all surveys [63]. This demonstrates that dietary patterns may show good reproducibility at the group level while individual classification remains unstable over time, potentially leading to significant misclassification in longitudinal studies.
Standardization Challenges Across Diverse Populations
The application of dietary pattern methodologies across diverse populations introduces significant standardization challenges that affect both reproducibility and interpretability of findings.
Cultural and Geographic Variability
A posteriori dietary patterns face particular challenges in cross-population comparisons because they are inherently population-specific. Patterns derived through principal components analysis reflect the predominant eating habits of the specific study population, which may not transfer directly to populations with different cultural food practices, availability, and preparation methods.
A priori patterns, while more standardized, face challenges in cultural appropriateness. The Mediterranean diet score, for instance, may not adequately capture healthy eating patterns in Asian populations where traditional dietary patterns differ significantly from Mediterranean cuisine.
Measurement Error and Within-Person Variability
All dietary assessment methods are subject to measurement errors that impact reproducibility:
- 24-hour recalls and food records capture short-term intake with significant day-to-day variability [64]
- FFQs aim to capture habitual intake but are subject to recall bias and portion size estimation errors [64]
- Systematic under-reporting of energy intake is pervasive across self-report methods, particularly among individuals with obesity [64]
The UK Biobank analysis emphasized that "failure to appreciate the importance of within-person variability in dietary intake will result in underestimation of associations with disease in population studies" [61]. Statistical methods such as regression calibration and measurement error models are essential to correct for these sources of error.
Methodological Heterogeneity
Substantial heterogeneity exists in the application of both a priori and a posteriori methods:
- A posteriori: Variations in food grouping, number of factors retained, rotation methods, and interpretation of patterns
- A priori: Differences in index construction, cutoff points, and component selection
- Assessment tools: Variability in FFQ design, portion size estimation, and nutrient databases
This methodological diversity complicates cross-study comparisons and meta-analyses, limiting the ability to draw consistent conclusions about diet-disease relationships.
Experimental Protocols for Enhanced Reproducibility
Standardized Dietary Pattern Derivation Protocol
Objective: To derive a posteriori dietary patterns using principal components analysis with standardized methodology to enhance reproducibility.
Materials:
- Validated food frequency questionnaire or multiple 24-hour recalls
- Statistical software (R, SAS, or SPSS)
- Standardized food grouping system
Procedure:
- Food Grouping: Aggregate individual food items into logically related food groups based on nutritional similarity and culinary use
- Energy Adjustment: Adjust food group intakes for total energy intake using the residual method
- Factor Extraction: Perform principal components analysis with varimax rotation
- Factor Retention: Determine number of factors to retain based on scree plot, eigenvalues >1.5, and interpretability
- Pattern Interpretation: Label patterns based on foods with highest factor loadings (absolute value >0.2)
- Reproducibility Assessment: Calculate internal consistency (Cronbach's alpha) and stability in split-half samples
Validation: Compare derived patterns with a priori patterns and biological markers where available
Cross-Population Comparison Protocol
Objective: To compare dietary patterns across diverse populations while maintaining methodological consistency.
Materials:
- Standardized assessment tools across populations
- Harmonized food composition databases
- Cultural adaptation protocols
Procedure:
- Tool Harmonization: Use standardized FFQ core items with population-specific additions
- Cultural Adaptation: Employ forward-backward translation and cognitive testing for dietary assessments
- Data Collection: Implement standardized training for interviewers across sites
- Pattern Application: Apply identical a priori scores to all populations
- Pattern Derivation: Derive a posteriori patterns separately for each population using identical statistical parameters
- Comparative Analysis: Compare pattern structures using congruence coefficients and pattern scores
Figure 1: Dietary Pattern Analysis Workflow
Comparative Predictive Performance: A Priori vs. A Posteriori Patterns
The comparative performance of a priori and a posteriori dietary patterns in predicting health outcomes has been directly evaluated in several studies. A case/case-control study comparing these approaches for predicting acute coronary syndrome (ACS) and ischemic stroke employed six classification algorithms to assess predictive accuracy [14] [26].
Table 4: Predictive Accuracy (C-Statistic) for Acute Coronary Syndrome and Stroke
| Classification Algorithm | A Priori (ACS) | A Posteriori (ACS) | A Priori (Stroke) | A Posteriori (Stroke) |
|---|---|---|---|---|
| Multiple Logistic Regression | 0.807 | 0.827 | 0.767 | 0.780 |
| Naïve Bayes | 0.706 | 0.724 | 0.748 | 0.744 |
| Decision Trees | 0.659 | 0.706 | 0.692 | 0.617 |
| RIPPER | 0.587 | 0.583 | 0.637 | 0.674 |
| Artificial Neural Networks | 0.724 | 0.730 | 0.749 | 0.744 |
| Support Vector Machines | 0.719 | 0.739 | 0.746 | 0.756 |
The study concluded that "both dietary pattern approaches achieved equivalent classification accuracy over most classification algorithms" [14] [26]. This suggests that the choice between methodologies should be based on the specific research question and application rather than assumed superiority of one approach.
The Scientist's Toolkit: Essential Research Reagents and Materials
Standardized tools and protocols are essential for enhancing reproducibility in dietary pattern research. The following table outlines key resources and their applications:
Table 5: Essential Research Reagents and Tools for Dietary Pattern Analysis
| Tool/Resource | Function | Application Notes | ||
|---|---|---|---|---|
| Harvard FFQ [62] | Semi-quantitative food frequency assessment | 40+ years of development; includes nutrient database | ||
| UK Biobank 24-h Dietary Assessment [61] | Web-based 24-hour recall | 206 food items; 32 drink types; 15 min completion time | ||
| MedDietScore [26] | A priori Mediterranean diet adherence | Range 0-9; includes fruit, vegetables, legumes, fish, wholegrains, MUFA:SFA ratio | ||
| Principal Components Analysis [26] | A posteriori pattern derivation | Varimax rotation; eigenvalue >1.5; factor loadings > | 0.2 | |
| Recovery Biomarkers [64] | Validation of self-reported intake | Doubly labeled water (energy); urinary nitrogen (protein) | ||
| Standardized Food Grouping System | Food aggregation for analysis | Culture-specific adaptations needed |
Technological Innovations and Future Directions
Emerging technologies offer promising approaches to address reproducibility challenges in dietary assessment:
Digital Dietary Assessment Tools
Web-based and mobile dietary assessment platforms like the Automated Self-Administered 24-hour recall (ASA-24) enable standardized data collection with reduced interviewer burden and cost [64]. These tools can incorporate digital photography, natural language processing, and portion size estimation algorithms to enhance accuracy.
Integration of Biomarkers
Recovery biomarkers (doubly labeled water for energy, urinary nitrogen for protein) and concentration biomarkers (plasma carotenoids, fatty acids) provide objective measures to correct for systematic measurement errors in self-reported dietary data [64]. Integration of these biomarkers into dietary pattern studies enhances validity and facilitates cross-population comparisons.
Machine Learning Approaches
Advanced classification algorithms including support vector machines, artificial neural networks, and decision trees show promise in enhancing the predictive accuracy of both a priori and a posteriori dietary patterns [26]. These methods can capture complex nonlinear relationships and interactions that traditional statistical approaches may miss.
Figure 2: Research Integrity Framework for Enhanced Reproducibility
The problem of reproducibility and standardization across populations presents significant challenges in dietary pattern research, but systematic approaches can enhance the reliability and comparability of findings. Key considerations for researchers include:
- Methodological Selection: Choose between a priori and a posteriori approaches based on research questions rather than assumed superiority
- Measurement Error Accounting: Implement statistical corrections for within-person variability and systematic measurement errors
- Standardized Protocols: Adopt harmonized methodologies for dietary assessment, food grouping, and pattern derivation
- Transparent Reporting: Document all methodological decisions and share protocols, code, and data where possible
- Cross-Population Validation: Validate dietary patterns across diverse populations using both biological and behavioral markers
As nutritional epidemiology evolves, integration of technological innovations, objective biomarkers, and standardized frameworks will enhance the reproducibility of dietary pattern research and strengthen the evidence base for dietary recommendations and public health policies across diverse populations.
Strategies for Selecting the Optimal Method Based on Research Questions
In dietary patterns research, the choice of analytical method is paramount and must be driven directly by the specific research question. The field is broadly divided into two methodological approaches: a priori (investigator-driven) and a posteriori (data-driven) methods [65]. A priori methods use predefined dietary patterns based on existing nutritional knowledge and scientific evidence, evaluating adherence through dietary indices or scores [7]. In contrast, a posteriori methods use multivariate statistical techniques to derive dietary patterns directly from population dietary intake data, identifying underlying structures and combinations of foods actually consumed by the study population [12]. Understanding the conceptual foundations, applications, and limitations of each approach is essential for designing robust nutritional epidemiology studies and generating clinically meaningful evidence for drug development and public health initiatives.
Methodological Approaches: A Detailed Comparison
A Priori (Investigator-Driven) Methods
A priori approaches assess adherence to predefined dietary patterns aligned with current dietary guidelines or scientific evidence about health and disease prevention [7]. These methods calculate dietary quality scores by summing individual scores assigned to specific dietary components.
Common A Priori Indices and Their Constructs:
- Healthy Eating Index (HEI): Measures adherence to the Dietary Guidelines for Americans [65].
- Alternative Healthy Eating Index (AHEI): Based on foods and nutrients predictive of chronic disease risk [7].
- Alternative Mediterranean Diet (aMED): Assesses adherence to the traditional Mediterranean diet pattern [7] [65].
- Dietary Approaches to Stop Hypertension (DASH): Scores alignment with the DASH diet, which is designed to prevent and control hypertension [7].
- Plant-Based Diet Indices (PDI, hPDI, uPDI): Evaluate the quality of plant-based diets, distinguishing between healthy and unhealthy plant foods [7].
Key Applications: A priori methods are particularly valuable for translating nutritional evidence into public health practice, as they directly evaluate adherence to recommended dietary guidelines [65]. They allow for comparison across different populations and studies because the scoring system is standardized and not specific to the study population's particular dietary habits.
A Posteriori (Data-Driven) Methods
A posteriori methods use statistical techniques to identify underlying dietary patterns from dietary intake data collected from a study population. These patterns are specific to the population being studied.
Common A Posteriori Techniques:
- Factor Analysis (FA) and Principal Component Analysis (PCA): The most commonly used a posteriori methods [65]. They reduce the dimensionality of dietary data by identifying a few factors or components (dietary patterns) that explain the maximum correlation or variance between different food groups [7]. These patterns are characterized by factor loadings, which represent the correlation between food groups and the derived pattern.
- Cluster Analysis (CA): Classifies individuals into mutually exclusive groups (clusters) based on the similarity of their overall dietary intake [65]. This method identifies population subgroups with distinct dietary profiles.
- Reduced Rank Regression (RRR): A hybrid method that derives patterns that explain the maximum variation in both dietary intake and a set of intermediate response variables (e.g., biomarkers or nutrient intakes) related to a specific disease outcome [65].
Key Applications: A posteriori methods are ideal for exploring and describing the predominant dietary cultures within a specific population without imposing preconceived hypotheses [3]. They can reveal novel dietary patterns that may be associated with health outcomes.
Comparative Analysis of Methodological Approaches
Table 1: Comparative characteristics of a priori and a posteriori dietary pattern methods.
| Feature | A Priori Methods | A Posteriori Methods |
|---|---|---|
| Core Concept | Investigator-driven based on prior knowledge [65] | Data-driven from population intake data [12] |
| Primary Goal | Measure adherence to predefined dietary guidelines | Describe existing dietary structures in a population |
| Output | A single score representing overall diet quality | Patterns (factors/clusters) specific to the study population |
| Comparability | High; allows cross-population comparisons [7] | Low; patterns are population-specific |
| Subjectivity | In the construction of the index and scoring system [7] | In decisions on food grouping, number of patterns, and naming [65] |
| Key Advantage | Direct relevance to dietary recommendations | Identifies real-world dietary combinations without preconceptions |
| Main Limitation | May miss important population-specific patterns | Results are less generalizable and comparable |
Strategic Selection Framework
Selecting the optimal dietary pattern analysis method is a critical step that should be guided by the study's primary research objective. The following workflow and decision matrix provide a structured approach to this selection process.
Decision Framework for Method Selection
Use A Priori Methods When:
- The goal is to test a specific hypothesis about a known diet-disease relationship (e.g., "Does adherence to the Mediterranean diet reduce the risk of Parkinson's disease?") [4].
- The research aims to evaluate compliance with established dietary guidelines or provide evidence for their update [65].
- Direct comparison of diet quality across different populations or studies is required [7].
Use A Posteriori Methods When:
- The research is exploratory, aiming to identify the predominant, real-world dietary patterns within a specific population without a strong prior hypothesis [3].
- The goal is to understand the dietary culture or food combinations unique to a demographic, geographic, or ethnic group.
- Investigating novel dietary patterns that may be associated with a health outcome, especially when existing dietary indices may not capture the relevant dietary exposure.
Experimental Protocols and Reporting Standards
Protocol for Implementing an A Priori Analysis
Step 1: Index Selection. Choose a dietary index that aligns with the research question (e.g., aMED for neurodegenerative disease, DASH for cardiovascular outcomes) [4] [65].
Step 2: Dietary Data Preparation. Code dietary intake data from FFQs, 24-hour recalls, or food records into the food groups and nutrients required by the selected index.
Step 3: Scoring. Apply the index's specific scoring algorithm. This involves defining cut-off points for each component (e.g., quintiles, median, or recommended intake levels). Scores can be absolute or data-driven, a decision that must be justified as it impacts results [65].
Step 4: Statistical Analysis. Use the total or component scores as the exposure variable in multivariate regression models (e.g., Cox proportional hazards for cohort studies) to estimate the risk of the health outcome, adjusting for relevant confounders like age, sex, BMI, and energy intake.
Protocol for Implementing an A Posteriori Analysis
Step 1: Food Grouping. Aggregate individual food items from dietary assessment tools into logically meaningful food groups (e.g., "whole grains," "red meat," "leafy green vegetables"). This step reduces complexity and collinearity [7].
Step 2: Method Application.
- For PCA/FA: Standardize food group intake (e.g., as grams/day adjusted for energy intake). Determine the number of patterns to retain based on eigenvalues (>1), scree plot interpretation, and interpretable variance [7]. Rotate factors (e.g., using Varimax) to improve interpretability.
- For Cluster Analysis: Choose a clustering algorithm (e.g., k-means) and a measure of distance. Determine the optimal number of clusters using statistical criteria (e.g., Calinski-Harabasz index) and clinical interpretability.
Step 3: Pattern Interpretation and Naming. Interpret the retained patterns by examining the factor loadings (for PCA/FA) or the mean intake of food groups across clusters (for CA). Name the patterns based on the food groups with the highest positive and negative loadings (e.g., "Prudent" pattern high in fruits/vegetables; "Western" pattern high in red meat and refined grains) [4] [3].
Step 4: Statistical Analysis. Use pattern scores (from PCA/FA) or cluster membership (from CA) as the exposure variable in models analyzing the health outcome.
Essential Reporting Standards
To ensure reproducibility and synthesis of evidence, studies must transparently report key methodological decisions [65].
- For A Priori Methods: Report the rationale for index selection, details of dietary components, scoring criteria (including cut-point definitions), and handling of energy intake.
- For A Posteriori Methods: Report the food grouping system, the rationale for retaining the number of patterns, factor loadings for key food groups, and the process of pattern naming. Providing a quantitative food and nutrient profile of the derived patterns is crucial for comparability [65].
Table 2: Key research reagents and resources for dietary pattern analysis.
| Tool/Reagent | Function/Description | Application Context |
|---|---|---|
| Food Frequency Questionnaire (FFQ) | A long-term assessment tool querying the frequency of consumption for a fixed list of foods over a reference period (e.g., past year) [64]. | Core dietary assessment method for large epidemiological studies, especially for a posteriori analysis. |
| 24-Hour Dietary Recall (24HR) | A short-term assessment where a trained interviewer probes for detailed intake over the previous 24 hours [64]. | Provides more precise intake data; multiple non-consecutive 24HRs can estimate usual intake. Used in validation. |
| Healthy Eating Index (HEI) | A definitive a priori index that measures adherence to the Dietary Guidelines for Americans [65]. | Gold standard for evaluating diet quality in US populations and for policy-relevant research. |
| Principal Component Analysis (PCA) | The most common multivariate statistical technique for deriving a posteriori dietary patterns [7] [65]. | Exploratory analysis to identify major, inter-correlated dietary patterns within a dataset. |
| Dietary Biomarkers (e.g., Recovery Biomarkers) | Objective measures of nutrient intake (e.g., doubly labeled water for energy, urinary nitrogen for protein) [64]. | The gold standard for validating and correcting for measurement error in self-reported dietary data. |
| Standardized Food Grouping System | A predefined schema for aggregating individual food items into nutritionally meaningful groups. | A critical first step in a posteriori analysis to reduce data dimensionality and avoid spurious patterns. |
The strategic selection between a priori and a posteriori dietary pattern methods is not a matter of one being superior to the other, but rather a deliberate choice dictated by the research question. A priori methods offer a powerful, hypothesis-driven tool for testing adherence to established dietary guidelines and facilitating cross-population comparisons. A posteriori methods provide an exploratory lens to discover real-world dietary structures and population-specific patterns. By applying a structured decision framework, adhering to rigorous experimental protocols, and employing comprehensive reporting standards, researchers can robustly characterize dietary exposures. This methodological precision is fundamental to generating reliable evidence that informs drug development, public health policy, and personalized nutritional strategies for disease prevention and management.
Emerging Methods and Future Directions in Dietary Pattern Analysis
Dietary pattern analysis has emerged as a cornerstone of nutritional epidemiology, moving beyond the limitations of single-nutrient or single-food studies to capture the synergistic effects of overall diet. This field is fundamentally structured around two complementary approaches: a priori and a posteriori analysis. A priori methods use pre-defined, hypothesis-driven indices based on existing scientific knowledge or dietary guidelines, such as the Mediterranean Diet Score (MedDietScore) or the Dietary Inflammatory Index (DII) [26] [23]. In contrast, a posteriori methods, including principal components analysis (PCA) and factor analysis, are data-driven, using multivariate statistics to derive eating patterns directly from consumption data without pre-conceived hypotheses [26] [4]. A recent meta-analysis on Parkinson's disease exemplifies this dual approach, simultaneously assessing a priori indices like the Mediterranean diet and a posteriori patterns like the "Healthy" and "Western" dietary patterns [4].
The central thesis of modern dietary pattern research is that both approaches provide valuable, complementary insights. A 2025 study concluded that both dietary pattern approaches achieved equivalent classification accuracy for predicting acute coronary syndrome and ischemic stroke across most machine learning algorithms [26]. However, the field is rapidly evolving. Traditional methods are being supplemented and, in some cases, supplanted by advanced computational techniques that can handle the immense complexity, non-linearity, and high-dimensionality of dietary data. This guide explores these emerging methodologies, providing a technical roadmap for researchers and scientists engaged in nutritional epidemiology, chronic disease prevention, and the development of targeted nutritional therapies.
Beyond Tradition: Limitations of Conventional Methods
Traditional dietary pattern analysis, while foundational, possesses significant methodological constraints that emerging approaches seek to overcome.
A Priori Limitations: A priori indices are inherently limited by existing scientific knowledge. They can only quantify adherence to dietary patterns that are already well-characterized, making them ill-suited for discovering novel, culturally specific, or emerging dietary patterns. Furthermore, they often treat dietary components as independent, typically ignoring the complex, non-linear interactions and synergies between different foods and nutrients [66]. For instance, a score might add points for fruit and vegetable consumption separately, but fail to capture the potential synergistic health effect of their combined consumption.
A Posteriori Limitations: While a posteriori methods like PCA are excellent for data reduction and describing population-level patterns, they come with their own set of challenges. They are highly dependent on the specific study population and the subjective decisions made during analysis (e.g., how to group foods, how many factors to retain, and how to label them). This limits the reproducibility and comparability of findings across different studies [66]. Furthermore, these methods often assume that dietary patterns are relatively static and do not adequately model how diets change over time due to aging, economic shifts, or health status [66].
A Shared Constraint: Both traditional approaches have historically relied on linear statistical models (e.g., multiple logistic regression) which are often inadequate for capturing the complex, non-linear relationships that define diet-disease interactions [26].
Table 1: Core Limitations of Traditional Dietary Pattern Analysis Methods
| Method Type | Key Limitations | Impact on Research |
|---|---|---|
| A Priori | - Relies on pre-existing knowledge- Blind to novel patterns- Often assumes linear, independent effects of foods | - Cannot discover new diet-disease relationships- May overlook important food synergies |
| A Posteriori | - Population-specific and subjective- Poor reproducibility across studies- Often assumes static dietary patterns | - Findings difficult to generalize- Limited ability to model dietary changes over time |
| Both | - Reliance on linear models- Difficulty handling high-dimensional data | - Incomplete modeling of complex, real-world diet-disease interactions |
The New Frontier: Advanced Computational and Network-Based Approaches
Machine Learning for Classification and Prediction
State-of-the-art machine learning (ML) algorithms are now being deployed to enhance the predictive accuracy of both a priori and a posteriori dietary patterns. These methods learn complex patterns from data, offering superior generalization for classifying disease outcomes based on dietary input.
A landmark case/case-control study directly compared the effectiveness of a priori (MedDietScore) and a posteriori (PCA-derived) patterns using six different classification algorithms [26]. The study predicted Acute Coronary Syndrome (ACS) and ischemic stroke in 1,000 participants. The key finding was that both dietary pattern approaches achieved equivalent classification accuracy across most algorithms, suggesting the choice of method depends on the specific research question rather than a inherent superiority of one over the other [26].
Table 2: Performance (C-Statistic) of Machine Learning Algorithms in Predicting ACS and Stroke from Dietary Patterns [26]
| Classification Algorithm | A-Priori (C-Statistic) | A-Posteriori (C-Statistic) | ||
|---|---|---|---|---|
| ACS | Stroke | ACS | Stroke | |
| Multiple Logistic Regression (MLR) | 0.807 | 0.767 | 0.827 | 0.780 |
| Naïve Bayes | 0.724 | 0.740 | 0.745 | 0.732 |
| Decision Trees | 0.614 | 0.655 | 0.654 | 0.617 |
| RIPPER | 0.587 | 0.637 | 0.583 | 0.669 |
| Artificial Neural Networks | 0.734 | 0.717 | 0.753 | 0.719 |
| Support Vector Machines | 0.724 | 0.703 | 0.745 | 0.714 |
This research demonstrates that ML models, particularly MLR and Neural Networks, can achieve high predictive accuracy (C-statistics >0.80 for ACS). It also highlights that algorithm choice is critical, with tree- and rule-based methods (RIPPER, Decision Trees) performing notably worse than others [26].
Network Analysis for Unveiling Food Synergies
Network analysis represents a paradigm shift from reducing diet to scores or factors to instead mapping the web of interactions between dietary components. This method visualizes and quantifies the complex conditional dependencies between foods, revealing how they are consumed in combination.
Primary Model: Gaussian Graphical Models (GGMs) are the most frequently used network approach, applied in 61% of studies according to a 2025 scoping review [66]. GGMs use partial correlations to estimate the relationships between two food items while conditioning on all other foods in the network. This helps distinguish direct associations from indirect ones that might be driven by a third food. A key strength is their ability to identify central nodes—highly connected foods that may play a disproportionately important role in the overall dietary pattern, making them potential high-impact targets for interventions [66].
Overcoming Methodological Challenges: The application of network analysis in nutrition is maturing. The same scoping review proposed five guiding principles to improve reliability [66]:
- Model Justification: The choice of network model (e.g., GGM, Mutual Information network) must be theoretically justified.
- Design-Question Alignment: The study design must align with the research question, with a noted over-reliance on cross-sectional data.
- Transparent Estimation: The use of regularization techniques like graphical LASSO (employed in 93% of GGM studies) to improve network clarity must be transparently reported.
- Cautious Metric Interpretation: Centrality metrics must be interpreted with caution, as 72% of studies used them without acknowledging their limitations.
- Robust Handling of Non-Normal Data: Methods like the Semiparametric Gaussian Copula Graphical Model (SGCGM) must be used to handle the non-normal data typical of dietary intake.
The following diagram illustrates the typical workflow for conducting a dietary network analysis, from data preparation to interpretation.
Integrating Approaches for a Comprehensive View
The most robust contemporary research integrates both a priori and a posteriori methods to triangulate findings and gain a more complete understanding. A 2025 prospective cohort study on lung cancer in the UK Biobank exemplifies this powerful synergy [23].
The study combined an a priori Dietary Inflammatory Index (DII) with a posteriori dietary patterns derived from factor analysis. It identified three patterns: a "Fruits and Vegetables" pattern, a "Cereals and Processed Foods" pattern, and a "Meat" pattern. The researchers then examined the correlation between these data-driven patterns and the hypothesis-driven DII [23].
They found a moderate negative correlation (Spearman's rho = -0.59) between the "Fruits and Vegetables" pattern score and the DII, meaning higher adherence to this pattern was associated with a more anti-inflammatory diet. The "Meat" pattern was weakly positively correlated with a pro-inflammatory diet. In fully adjusted models, a higher DII (pro-inflammatory diet) and a higher "Meat" pattern score were associated with a 17% and 18% increased risk of lung cancer, respectively. Conversely, the "Fruits and Vegetables" pattern was associated with a 22% lower risk [23]. This integration provides compelling evidence that the protective effect of a plant-based diet may be mechanistically linked to reducing dietary inflammation.
Application in Disease Prevention and Healthy Aging
Advanced dietary pattern research is critically informing our understanding of chronic disease prevention and the promotion of healthy aging. A 2025 meta-analysis of 11 studies on Parkinson's disease found that adherence to a priori patterns like the Mediterranean diet and a posteriori "Healthy" patterns were associated with a 13-24% reduced risk of Parkinson's disease, while a "Western" pattern was associated with a 54% increased risk [4].
Furthermore, a landmark study in Nature Medicine (2025) followed over 100,000 participants for 30 years to examine the association between eight different dietary patterns and "healthy aging"—a multidimensional construct encompassing freedom from chronic diseases and intact cognitive, physical, and mental health [17].
The study compared a priori scores including the Alternative Healthy Eating Index (AHEI), Mediterranean-DASH (aMED), DASH, MIND, and a healthful Plant-Based Diet Index (hPDI). It found that higher adherence to any of these patterns was strongly associated with greater odds of healthy aging. The AHEI showed the strongest association, with individuals in the highest quintile of adherence having 86% greater odds of healthy aging compared to those in the lowest quintile [17]. This provides powerful evidence that long-term dietary habits have a profound impact on overall health and well-being in later life.
Table 3: Association Between High Adherence to Dietary Patterns and Odds of Healthy Aging [17]
| Dietary Pattern | Odds Ratio (OR) for Healthy Aging(Highest vs. Lowest Quintile) | 95% Confidence Interval |
|---|---|---|
| Alternative Healthy Eating Index (AHEI) | 1.86 | 1.71 - 2.01 |
| Alternative Mediterranean Diet (aMED) | 1.78 | 1.64 - 1.93 |
| DASH Diet | 1.75 | 1.61 - 1.90 |
| MIND Diet | 1.68 | 1.55 - 1.82 |
| Planetary Health Diet (PHDI) | 1.62 | 1.49 - 1.76 |
| Healthful Plant-Based Diet (hPDI) | 1.45 | 1.35 - 1.57 |
Experimental Protocols and Research Toolkit
Detailed Methodology for a Combined Analysis
The following is a synthesis of the core methodological steps for conducting an integrated a priori and a posteriori dietary pattern analysis, as used in recent high-impact studies [26] [23].
- Study Population and Design: A prospective cohort or case-control design is established. For example, the UK Biobank lung cancer study included 189,561 participants [23], while the ACS/stroke study used a case-control design with 250 cases and 250 controls per outcome [26].
- Dietary Assessment:
- Tool: Use validated food frequency questionnaires (FFQs) or multiple 24-hour dietary recalls.
- Data Conversion: Convert consumed foods into nutrients and food groups using a standardized food composition database (e.g., USDA Food and Nutrient Database for Dietary Studies - FNDDS) [49].
- Deriving Dietary Patterns:
- A Priori: Calculate predefined scores (e.g., MedDietScore, DII) based on established algorithms and the collected dietary data [26] [23].
- A Posteriori: Perform factor analysis or principal component analysis on the food group data.
- Preprocessing: Adjust food intake for total energy. Check suitability with KMO test and Bartlett's test of sphericity.
- Extraction: Retain factors/components based on scree plot, eigenvalues >1.5-2.0, and interpretability.
- Rotation: Use orthogonal (e.g., Varimax) or oblique (e.g., Promax) rotation to achieve a simpler structure.
- Labeling: Label patterns based on food groups with high factor loadings (e.g., >|0.2| or |0.3|) [23].
- Statistical Modeling and Machine Learning:
- Correlation Analysis: Examine correlations between a priori scores and a posteriori pattern scores using Spearman's correlation [23].
- Modeling Disease Risk: Use Cox proportional hazards regression (for cohort studies) or multiple logistic regression (for case-control studies) to assess associations between dietary patterns and health outcomes, adjusting for confounders like age, sex, BMI, and smoking status [23].
- Machine Learning: Partition data into training and testing sets. Train multiple classification algorithms (e.g., MLR, SVM, Neural Networks) using dietary pattern scores as inputs and disease status as the output. Evaluate performance using metrics like the C-statistic [26].
- Validation: Validate a posteriori patterns through split-sample validation or reproducibility over time. Validate ML models using k-fold cross-validation.
The Scientist's Toolkit: Essential Research Reagents and Materials
Table 4: Key Resources for Advanced Dietary Pattern Analysis
| Tool/Resource | Category | Function in Research |
|---|---|---|
| 24-Hour Dietary Recall | Dietary Assessment | Gold-standard method for collecting detailed dietary intake data; used in NHANES [49]. |
| Food Frequency Questionnaire (FFQ) | Dietary Assessment | Practical tool for assessing habitual diet over a long period in large epidemiological studies [17]. |
| USDA FNDDS & FPED | Database | Converts reported foods into nutrients (FNDDS) and standardizes food groups (FPED) for consistent analysis [49]. |
| NHANES / UK Biobank Datasets | Data Resource | Large, representative, publicly available datasets with detailed dietary and health data for analysis and validation. |
| Graphical LASSO (glasso) | Software Package | R package for applying LASSO regularization to estimate sparse Gaussian Graphical Models of food co-consumption [66]. |
| Scikit-learn / WEKA | Software Library | Comprehensive libraries for implementing machine learning classifiers (e.g., SVM, Naïve Bayes, Neural Networks) [26]. |
| Cox Proportional Hazards Model | Statistical Model | Standard for analyzing time-to-event data (e.g., disease incidence) in prospective cohort studies [23] [17]. |
The workflow for implementing these tools in a comprehensive analysis is visualized below, showing the path from raw data to actionable insights.
The field of dietary pattern analysis is poised for several transformative shifts. A major future direction is the move beyond cross-sectional static patterns to dynamic, time-varying networks that can model how an individual's diet and its health impacts evolve over their lifespan [66]. Furthermore, the concept of the Planetary Health Diet underscores a growing imperative to develop dietary patterns that are not only healthy for people but also sustainable for the planet [67]. Future research will need to integrate these dual objectives into both a priori indices and a posteriori modeling.
Another key direction is the improved handling of what might be called "nutritional dark matter"—the vast number of uncharacterized bioactive compounds and complex food synergies that are invisible to traditional, knowledge-based prescriptive models. Data-driven, bottom-up approaches like network analysis are superior for discovering these complex interactions directly from real-world eating behaviors [66].
In conclusion, the dichotomy between a priori and a posteriori dietary pattern analysis is becoming less of a rivalry and more of a collaboration. The future lies in the integration of multiple methods—hypothesis-driven scores, data-driven patterns, machine learning classifiers, and network models—to build a more robust, nuanced, and actionable understanding of the complex relationship between diet and human health. This multi-pronged, technically sophisticated approach will ultimately empower more effective public health recommendations, personalized nutrition strategies, and informed drug development targeting diet-related chronic diseases.
Validating Patterns and Comparing Predictive Power for Health Outcomes
Nutritional epidemiology has progressively shifted from analyzing individual nutrients to examining whole dietary patterns, recognizing that foods and nutrients are consumed in complex combinations with synergistic and antagonistic effects. This analysis is primarily conducted through two methodological approaches: a priori (hypothesis-driven) and a posteriori (exploratory or data-driven) methods.
- A Priori Methods: Involve assessing an individual's adherence to a pre-defined dietary pattern or index, based on existing knowledge about food and disease relationships. These patterns are developed from dietary guidelines or culturally defined eating patterns, such as the Mediterranean Diet or the Healthy Eating Index (HEI). A priori scores gauge the level of adherence to a pattern considered "healthy" based on prior scientific evidence [68] [69] [10].
- A Posteriori Methods: Use multivariate statistical techniques, such as principal component analysis (PCA), factor analysis, or cluster analysis, to derive dietary patterns empirically from the dietary intake data of a study population. Common patterns identified through this method include "Western/Unhealthy" patterns (high in red/processed meats, refined grains, and sugary foods) and "Prudent/Healthy" patterns (high in fruits, vegetables, and whole grains). This approach reflects the population's actual dietary habits without a pre-defined hypothesis [68] [69].
This whitepaper synthesizes evidence from recent meta-analyses, framed within the context of this methodological dichotomy, to elucidate the relationships between dietary patterns and the risk of Parkinson's disease and gastric cancer.
Dietary Patterns and Parkinson's Disease Risk
Key Meta-Analysis Findings
Recent systematic reviews and meta-analyses of observational studies provide compelling evidence on the association between dietary patterns and Parkinson's Disease (PD) risk. The table below summarizes the pooled risk ratios (RR) for the highest versus lowest adherence categories.
Table 1: Association between Dietary Patterns and Parkinson's Disease Risk from Meta-Analyses
| Dietary Pattern | Type of Pattern | Risk Ratio (RR) | 95% Confidence Interval | p-value |
|---|---|---|---|---|
| Mediterranean Diet | A Priori | 0.87 | 0.78 - 0.97 | 0.017 |
| Healthy Dietary Index | A Priori | 0.76 | 0.65 - 0.91 | 0.002 |
| Healthy/Prudent Pattern | A Posteriori | 0.76 | 0.62 - 0.93 | 0.007 |
| Western Dietary Pattern | A Posteriori | 1.54 | 1.10 - 2.15 | 0.011 |
A separate dose-response meta-analysis of prospective cohort studies further quantified the risk associated with specific food groups [70]:
- Dairy: A 100-gram/day increase in intake was associated with a 5-7% increased PD risk. High consumption (vs. low) showed a 26% increased risk (OR: 1.26, 95% CI: 1.12-1.41).
- Legumes and Nuts: This was the only food group showing a reduced PD risk (OR: 0.71, 95% CI: 0.62-0.81).
Methodological Protocols for PD Dietary Research
The evidence in Table 1 is derived from observational studies adhering to rigorous protocols.
- Study Design & Population: Typically prospective cohort studies involving hundreds of thousands of participants. For example, one reviewed meta-analysis included 326,751 participants and 2,524 PD cases from cohort, case-control, and cross-sectional studies [22].
- Exposure Assessment: Dietary intake is primarily assessed using Food Frequency Questionnaires (FFQs), which evaluate habitual intake over a long reference period (e.g., the past year). This tool is cost-effective for large sample sizes. The dietary patterns are then defined:
- A Priori: Using predefined scores (e.g., Mediterranean Diet Score).
- A Posteriori: Using factor analysis or principal component analysis on the FFQ data to identify population-specific patterns [64].
- Outcome Assessment: PD diagnosis must be confirmed by medical record review or a neurologist [22].
- Data Analysis: The most adjusted risk estimates (Hazard Ratios, Odds Ratios) are extracted. Pooled RRs are calculated for the highest versus lowest categories of adherence. Heterogeneity is assessed using Cochran’s Q test and I² statistic. Study quality is evaluated with tools like the Newcastle-Ottawa Scale (NOS), with scores ≥7 indicating high quality [22].
Dietary Patterns and Gastric Cancer Risk
Key Meta-Analysis Findings
Evidence linking dietary patterns to Gastric Cancer (GC) risk is also robust, with clear distinctions between healthy and unhealthy patterns. The following table summarizes the associations based on a posteriori dietary patterns.
Table 2: Association between A Posteriori Dietary Patterns and Gastric Cancer Risk
| Dietary Pattern | Description | Odds Ratio (OR) | 95% Confidence Interval | Subsite Analysis |
|---|---|---|---|---|
| Prudent/Healthy | High in vegetables and fruits. | 0.75 | 0.63 - 0.90 | N/A |
| Western/Unhealthy | High in red/processed meats, sugary beverages, refined carbs. | 1.51 | 1.21 - 1.89 | Cardia GC: OR 2.05 (1.51-2.78); Distal GC: OR 1.36 (1.07-1.73) |
Another meta-analysis of 23 studies confirmed these findings, showing that a "Healthy" pattern reduced GC risk (OR: 0.69), while an "Unhealthy" pattern increased it (OR: 1.59) [68].
Methodological Protocols for GC Dietary Research
The methodologies mirror those used in PD research, with some specific considerations.
- Exposure Assessment: A posteriori patterns are derived from FFQ data using statistical methods. The "Western" pattern is consistently characterized by high intake of red/processed meats, sugary beverages, and refined carbohydrates, while the "Prudent" pattern is defined by high intake of vegetables and fruits [68].
- Outcome Assessment: Gastric cancer incidence is the primary outcome.
- Data Analysis & Confounding: Analyses are adjusted for key potential confounders, including Helicobacter pylori infection status, a major risk factor for GC. The association between unhealthy patterns and GC risk is notably stronger for cardia gastric cancer than for distal gastric cancer [68].
The Scientist's Toolkit: Key Research Reagent Solutions
Table 3: Essential Reagents and Tools for Dietary Pattern and Disease Research
| Tool/Reagent | Function/Application in Research |
|---|---|
| Food Frequency Questionnaire (FFQ) | A long-term dietary assessment tool to capture habitual intake of food items and groups over a specified period (e.g., past year). It is the primary data source for deriving both a priori and a posteriori patterns [64]. |
| 24-Hour Dietary Recall (24HR) | A short-term assessment tool to capture detailed intake over the previous 24 hours. Multiple non-consecutive 24HRs can estimate usual intake and are used to calculate a priori metrics like the Healthy Eating Index [64]. |
| Mediterranean Diet Score (MDS) | A specific, validated a priori index used to quantify an individual's adherence to the traditional Mediterranean dietary pattern [69] [10]. |
| Healthy Eating Index (HEI) | An a priori index based on U.S. Dietary Guidelines, used to assess overall diet quality and compliance with national recommendations [68]. |
| Principal Component Analysis (PCA) / Factor Analysis | A statistical software algorithm used to identify a posteriori dietary patterns from FFQ data by reducing numerous food items into a few core patterns based on correlation [68] [10]. |
| Newcastle-Ottawa Scale (NOS) | A quality assessment tool for non-randomized studies in meta-analyses, evaluating selection, comparability, and outcome of study cohorts [22]. |
Experimental Workflow and Analytical Logic
The following diagram illustrates the standard workflow for conducting research on dietary patterns and disease risk, integrating both a priori and a posteriori approaches.
Diagram 1: Dietary Pattern and Disease Research Workflow
Logical Framework for Dietary Pattern Analysis
The conceptual relationship between the two methodological approaches and their link to disease outcomes is mapped below.
Diagram 2: Logical Framework of Dietary Patterns and Disease Risk
Evidence from meta-analyses consistently demonstrates that healthy dietary patterns, whether defined a priori (Mediterranean Diet, Healthy Eating Index) or a posteriori (Prudent/Healthy pattern), are associated with a significant reduction in the risk of both Parkinson's disease and gastric cancer. Conversely, unhealthy patterns, particularly the a posteriori-derived Western dietary pattern, are linked to a markedly increased risk.
The choice between a priori and a posteriori methods depends on the research question. The a priori approach is powerful for testing specific hypotheses about adherence to recommended diets, while the a posteriori approach is invaluable for discovering real-world dietary practices and their health impacts. Both methodologies provide complementary and robust evidence that underscores the critical role of overall diet quality in chronic disease prevention. Future research should focus on well-designed prospective studies and randomized controlled trials to further elucidate causal relationships and refine dietary guidance.
In nutritional epidemiology, two principal methodological approaches are employed to elucidate the relationship between diet and disease risk: a priori and a posteriori dietary pattern analysis. These paradigms represent fundamentally different philosophies for quantifying dietary exposure and have distinct implications for research and clinical practice. A priori patterns are hypothesis-oriented, predefined based on existing scientific knowledge or dietary guidelines. They include indices such as the Dietary Inflammatory Index (DII), the Mediterranean Diet Score (aMED), and the Healthy Eating Index (HEI), which assign scores to individuals based on their adherence to a predetermined ideal dietary pattern [71] [23]. In contrast, a posteriori patterns are data-driven and exploratory, derived empirically from dietary intake data of a specific study population using statistical techniques like factor analysis or cluster analysis. These patterns, such as "Fruits and Vegetables" or "Western" patterns, reflect the actual, common eating habits within a cohort [4] [23].
Understanding the comparative performance, strengths, and limitations of these approaches is crucial for researchers and public health professionals aiming to predict the risk of chronic diseases accurately. This guide provides an in-depth technical comparison of these methodologies, detailing their experimental protocols, predictive performance across various health outcomes, and practical implementation.
Methodological Protocols and Experimental Workflows
A Priori Method Protocol: Calculating the Dietary Inflammatory Index (DII)
The DII quantifies the inflammatory potential of an individual's overall diet based on a global literature review of dietary components' effects on inflammatory biomarkers [71].
Experimental Protocol:
- Dietary Assessment: Collect dietary intake data using a validated 24-hour dietary recall or a food frequency questionnaire (FFQ).
- Data Standardization: Link the reported food consumption to a global database of mean dietary intake for 45 food parameters to create a Z-score for each parameter.
- Inflammatory Effect Scoring: Multiply each Z-score by the corresponding "inflammatory effect score" (ranging from +1 for pro-inflammatory to -1 for anti-inflammatory), derived from the literature review.
- Index Calculation: Sum the products for all available food parameters to generate an overall DII score for each participant. Scores range from +7.98 (most pro-inflammatory) to -8.87 (most anti-inflammatory) [71].
- Statistical Analysis: In epidemiological analyses, DII scores are typically categorized into tertiles, quartiles, or quintiles. The association between DII scores and disease risk is then evaluated using Cox proportional hazards regression models, adjusting for confounders such as age, sex, BMI, and smoking status. The results are expressed as hazard ratios (HRs) with 95% confidence intervals (CIs) [23].
A Posteriori Method Protocol: Deriving Patterns via Factor Analysis
This data-driven approach identifies common dietary patterns that exist within the study population without pre-specified hypotheses.
Experimental Protocol:
- Dietary Data Preparation: Collect dietary intake data and aggregate individual food items into predefined food groups (e.g., fruits, vegetables, red meat, whole grains) to reduce complexity.
- Factor Extraction: Perform factor analysis (or principal component analysis) on the correlation matrix of the food groups. The suitability of the data for factor analysis is confirmed using the Kaiser-Meyer-Olkin (KMO) measure and Bartlett's test of sphericity [23].
- Factor Rotation and Labeling: Apply a rotation method (e.g., Varimax) to make the factor structure more interpretable. Retain factors based on eigenvalues (typically >1), scree plots, and interpretability. Label each retained factor based on the food groups with the highest factor loadings (e.g., "Fruits and Vegetables," "Meat," "Cereals and Processed Foods") [23].
- Pattern Score Calculation: Calculate a factor score for each participant for each identified dietary pattern, representing their adherence to that pattern.
- Statistical Analysis: The association between these pattern scores and disease risk is analyzed similarly to the a priori method, using multivariable-adjusted regression models [23].
Table 1: Key Characteristics of A Priori and A Posteriori Dietary Patterns
| Feature | A Priori Patterns (e.g., DII, aMED, HEI) | A Posteriori Patterns (e.g., Factor Analysis) |
|---|---|---|
| Basis | Existing scientific knowledge, dietary guidelines, or biological mechanisms. | Empirically derived from the study population's dietary data. |
| Hypothesis | Hypothesis-driven; tests a specific theory about a "healthy" or "pro-inflammatory" diet. | Exploratory; identifies what people actually eat without a pre-defined ideal. |
| Generalizability | High, as the scoring system is universally applicable across different populations. | Population-specific; patterns may vary significantly between different cohorts. |
| Interpretability | Straightforward, as components and scoring are predefined and justified by prior research. | Requires interpretation and labeling by researchers, which can be subjective. |
| Examples | Dietary Inflammatory Index (DII), Mediterranean Diet Score (aMED), Healthy Eating Index (HEI) [71] [23]. | "Fruits and Vegetables" pattern, "Western" pattern, "Meat" pattern [4] [23]. |
Diagram 1: Workflow for comparative analysis of dietary patterns.
Comparative Predictive Performance Across Health Outcomes
Neurodegenerative Disease: Parkinson's Disease Risk
A 2025 meta-analysis of 11 observational studies provided a direct comparison of how different patterns predict Parkinson's disease risk [4].
Table 2: Dietary Patterns and Parkinson's Disease Risk (Highest vs. Lowest Adherence)
| Dietary Pattern | Type | Relative Risk (RR) | 95% Confidence Interval | P-value |
|---|---|---|---|---|
| Mediterranean Diet | A Priori | 0.87 | 0.78 – 0.97 | 0.017 |
| Healthy Dietary Index | A Priori | 0.76 | 0.65 – 0.91 | 0.002 |
| Healthy Dietary Pattern | A Posteriori | 0.76 | 0.62 – 0.93 | 0.007 |
| Western Dietary Pattern | A Posteriori | 1.54 | 1.10 – 2.15 | 0.011 |
The data demonstrates that both a priori indices (Mediterranean Diet, Healthy Dietary Index) and the a posteriori-derived "Healthy Dietary Pattern" are significantly associated with a reduced risk of Parkinson's disease, with remarkably similar protective effects (RR ~0.76-0.87). Conversely, the data-driven "Western Dietary Pattern" is a strong predictor of increased risk [4].
Cancer: Lung Cancer Risk
A large prospective cohort study in the UK Biobank combined both approaches, identifying a posteriori patterns and calculating the a priori DII [23].
Table 3: Dietary Patterns and Lung Cancer Risk (Highest vs. Lowest Tertile of Adherence/Score)
| Dietary Pattern / Index | Type | Hazard Ratio (HR) | 95% Confidence Interval | P for trend |
|---|---|---|---|---|
| Dietary Inflammatory Index (DII) | A Priori | 1.17 | 1.00 – 1.36 | 0.035 |
| Fruits & Vegetables Pattern | A Posteriori | 0.78 | 0.67 – 0.91 | 0.002 |
| Meat Dietary Pattern | A Posteriori | 1.18 | 1.02 – 1.37 | 0.046 |
| Cereals & Processed Foods | A Posteriori | 0.97 | 0.83 – 1.12 | 0.658 |
The study found that a higher, more pro-inflammatory DII score was associated with a 17% increased risk of lung cancer. This finding was complemented by the a posteriori analysis: the "Meat" pattern was associated with an 18% increased risk, while the "Fruits and Vegetables" pattern was associated with a 22% reduced risk. The "Cereals and Processed Foods" pattern showed no significant association. This synergy provides a more nuanced understanding, linking the pro-inflammatory "Meat" pattern with the mechanistic pathway measured by the DII [23].
Cardiovascular and All-Cause Mortality
Research in individuals with cardiovascular disease (CVD) and diabetes has further highlighted the predictive utility of a priori indices. A 2025 study of 9,101 CVD patients found that higher scores on the AHEI, DASH, HEI-2020, and aMED were all significantly associated with a reduced risk of all-cause mortality, with Hazard Ratios for the highest tertile ranging from 0.59 to 0.75. Conversely, a higher DII score was associated with a 58% increased mortality risk (HR=1.58) [71].
For diabetes management, predictive models using LASSO regression and Random Forest algorithms identified dietary fiber and magnesium as the two most critical nutrients for reducing long-term all-cause and cardiovascular mortality. Nomogram models based on these nutrients demonstrated significant predictive value, underscoring the power of data-driven approaches to pinpoint specific actionable dietary components [72].
The Scientist's Toolkit: Essential Reagents and Research Solutions
Table 4: Key Reagents and Tools for Dietary Pattern Research
| Tool / Reagent | Function/Description | Application in Research |
|---|---|---|
| 24-Hour Dietary Recall | A structured interview to detail all foods and beverages consumed in the preceding 24 hours. | The primary method for individual-level dietary assessment in studies like NHANES and UK Biobank [71] [23] [72]. |
| Food Frequency Questionnaire (FFQ) | A self-administered questionnaire listing foods with frequency and portion size sections. | Used for estimating habitual long-term dietary intake in large cohort studies [4]. |
| Dietary Inflammatory Index (DII) Calculator | A standardized algorithm based on 45 food parameters and their effect on inflammatory biomarkers. | Quantifies the inflammatory potential of a diet for hypothesis-testing on inflammation-mediated diseases [71] [23]. |
| HEI-2020, aMED, DASH Scoring Algorithms | Predefined scoring systems that measure adherence to specific dietary guidelines or patterns. | Used as a priori indices to assess diet quality and its association with health outcomes [71]. |
| Statistical Software (R, SAS, STATA) | Platforms with packages for advanced statistical analysis, including factor analysis and Cox regression. | Essential for performing factor analysis, calculating dietary scores, and running multivariate regression models [4] [23] [72]. |
| NHANES Dietary Data | Publicly available datasets with comprehensive dietary intake and health data from a US representative sample. | A primary resource for conducting nutritional epidemiology and validating predictive models [71] [72]. |
Diagram 2: Proposed pathway from dietary patterns to disease risk.
Both a priori and a posteriori dietary pattern analysis methods provide powerful and complementary evidence for predicting disease risk. A priori indices offer a consistent, hypothesis-driven framework grounded in biological mechanisms (e.g., inflammation), making them ideal for targeted research and cross-population comparisons. A posteriori patterns capture the real-world complexity of dietary habits within specific populations, often identifying novel risk factors and confirming the practical implications of a priori findings.
The convergence of evidence—showing that healthy patterns (whether predefined or data-driven) consistently reduce the risk of chronic diseases, while Western/pro-inflammatory patterns increase it—strengthens the scientific foundation for dietary public health recommendations. For optimal predictive performance and a holistic understanding, future research should strategically integrate both methodological approaches.
The Role of the Dietary Inflammatory Index (DII) as an A Priori Tool
In nutritional research, the holistic assessment of diet is crucial for understanding complex diet-disease relationships. Two principal methodologies have emerged for this purpose: a priori and a posteriori dietary pattern analysis [4] [26]. A posteriori (data-driven) approaches use statistical methods like principal component analysis to derive dietary patterns specific to a study population [26]. In contrast, a priori approaches define dietary patterns based on pre-existing scientific knowledge, dietary guidelines, or hypotheses about diet-disease relationships before data analysis [73] [26]. The Dietary Inflammatory Index (DII) represents a significant advancement in a priori methodology by quantifying the inflammatory potential of diet based on current understanding of nutrition and inflammation biology [74]. This tool provides a standardized, hypothesis-driven approach for evaluating how diet influences chronic inflammation—a key pathway in the development of numerous chronic diseases [74] [75].
Theoretical Foundation: A Priori vs. A Posteriori Dietary Patterns
A priori dietary patterns are developed based on external evidence or predefined hypotheses, whereas a posteriori patterns emerge from statistical analysis of dietary intake data within a specific dataset [26]. The DII is firmly rooted in the a priori approach, as its development relied on existing scientific literature linking dietary components to inflammatory biomarkers [74].
Comparative analysis of dietary pattern approaches reveals that both a priori and a posteriori methods demonstrate similar predictive accuracy for disease outcomes. A study comparing these approaches for predicting acute coronary syndrome and ischemic stroke found equivalent classification accuracy across most machine learning algorithms [26]. However, the a priori approach of the DII offers distinct advantages for research applications, particularly its standardized methodology which enables direct comparison across different populations and studies [74] [73].
Table 1: Comparison of A Priori and A Posteriori Dietary Pattern Approaches
| Feature | A Priori Approach (DII) | A Posteriori Approach |
|---|---|---|
| Basis | Pre-defined hypothesis or scientific evidence [73] [26] | Statistical patterns in specific dataset [26] |
| Development | Based on literature review of diet-inflammatory biomarker relationships [74] | Derived via factor analysis, principal components analysis [4] [26] |
| Standardization | High - can be applied consistently across populations [73] | Low - pattern specific to each study population [26] |
| Hypothesis Testing | Directly tests predefined hypotheses | Exploratory - generates hypotheses |
| Interpretability | Clear biological rationale (inflammatory potential) [74] | Context-dependent interpretation |
| Examples | DII, Mediterranean Diet Score [4] | "Western", "Prudent" patterns [4] |
The diagram below illustrates the conceptual relationship between different dietary pattern approaches and their applications:
Figure 1: Classification and Applications of Dietary Pattern Approaches
The Dietary Inflammatory Index: Development and Methodology
Theoretical Foundation and Development Process
The DII was developed through a systematic review of nearly 2,000 research articles published between 1950 and 2007 that investigated associations between dietary components and inflammatory biomarkers [75]. This comprehensive literature analysis identified 45 food parameters with robust evidence regarding their effects on inflammation [76]. The index was designed to quantify the inflammatory potential of an individual's overall diet by synthesizing current scientific understanding of how specific dietary components modulate inflammatory pathways [74].
The development process established a global reference database representing average intakes of these 45 parameters across 11 populations worldwide [76]. This reference framework allows for standardized calculation of DII scores across different populations, addressing a significant limitation of population-specific a posteriori dietary patterns [74] [73]. The DII algorithm calculates a score based on how an individual's intake of each dietary component compares to the global standard, weighted by the component's reported effect on inflammatory biomarkers [76].
Calculation Method and Biomarker Basis
DII calculation follows a specific multi-step methodology. First, dietary intake data is collected, typically through food frequency questionnaires or 24-hour recalls. The intake of each food parameter is then compared to the global standard database to create a z-score, which is converted to a percentile and centered to minimize the effect of right skewing [76]. This value is multiplied by the respective inflammatory effect score for each food parameter, and all values are summed to create the overall DII score [76].
The inflammatory effect scores are derived from the literature review and represent the strength of evidence linking each dietary component to six key inflammatory biomarkers: C-reactive protein (CRP), IL-1β, IL-4, IL-6, IL-10, and tumor necrosis factor-α (TNF-α) [75]. Lower DII scores represent more anti-inflammatory diets, while higher scores indicate more pro-inflammatory diets [75].
Table 2: Key Inflammatory Biomarkers Underlying DII Development
| Biomarker | Biological Role | Direction in Inflammation | Dietary Modulators |
|---|---|---|---|
| C-reactive Protein (CRP) | Acute-phase protein produced by liver | Increases with inflammation [73] | Fiber, antioxidants, saturated fat [73] [77] |
| Interleukin-6 (IL-6) | Pro-inflammatory cytokine | Increases with inflammation [73] | Trans fats, refined carbohydrates [73] |
| TNF-α | Pro-inflammatory cytokine | Increases with inflammation [73] | Omega-3 fatty acids, antioxidants [73] |
| IL-1β | Pro-inflammatory cytokine | Increases with inflammation [77] | Mediterranean diet components [77] |
| IL-4 | Anti-inflammatory cytokine | Decreases with inflammation | Polyunsaturated fatty acids |
| IL-10 | Anti-inflammatory cytokine | Decreases with inflammation | Polyphenols, fiber |
The DII development workflow can be visualized as follows:
Figure 2: DII Development and Calculation Workflow
Validation and Refinement of the DII
Empirical Validation Studies
The construct validity of the DII has been tested in numerous studies across diverse populations. One significant validation effort led to the development of the Empirical Dietary Inflammatory Pattern (EDIP), which used reduced rank regression followed by stepwise linear regression to identify a dietary pattern most predictive of plasma inflammatory markers including IL-6, CRP, and TNF-α receptor 2 [73]. This research, conducted in the Nurses' Health Study, identified 18 food groups (9 anti-inflammatory and 9 pro-inflammatory) that collectively predicted inflammatory biomarker levels [73].
The EDIP was subsequently validated in two independent cohorts—the Nurses' Health Study II and the Health Professionals Follow-up Study—where it significantly predicted concentrations of all inflammatory biomarkers tested [73]. For example, comparing extreme EDIP quintiles in NHS-II revealed a 52% higher CRP level and 12% lower adiponectin level in those with the most pro-inflammatory diets [73]. This independent validation confirmed the DII's ability to assess the inflammatory potential of whole diets in both women and men.
Refinements and Related Indices
The DII framework has evolved to include complementary indices that address specific biological pathways. The Composite Dietary Antioxidant Index (CDAI) was developed to assess oxidative stress balance by incorporating six antioxidant nutrients: selenium, zinc, and vitamins A, C, and E [76]. Recent research has demonstrated that both DII and CDAI are independently associated with conditions like erectile dysfunction, with the TyG index and metabolic syndrome serving as mediating factors [76].
More comprehensive indices have also emerged, such as the Dietary and Lifestyle Inflammation Score (DLIS), which integrates both dietary inflammation scores and lifestyle factors including physical activity, BMI, and smoking status [78]. Studies have shown that DLIS provides enhanced predictive capability for conditions like polycystic ovary syndrome compared to DII alone [78].
Applications in Clinical Research and Disease Prediction
Evidence from Observational Studies
The DII has demonstrated significant utility in predicting various disease outcomes across multiple research contexts. A large-scale prospective cohort study of 189,561 participants from the UK Biobank with median follow-up of 9.45 years found that higher DII scores were associated with increased lung cancer risk [23]. Participants in the highest DII tertile had a 17% higher risk of lung cancer compared to those in the lowest tertile [23]. The same study identified a posteriori dietary patterns, finding that a "fruits and vegetables" pattern was associated with lower lung cancer risk, while a "meat" pattern was associated with higher risk [23].
In neurological research, a 2025 meta-analysis of 11 observational studies with 326,751 participants found that healthy dietary patterns (including anti-inflammatory diets) were associated with significantly reduced Parkinson's disease risk, while pro-inflammatory Western dietary patterns increased risk [4]. Similar findings have emerged for metabolic conditions, with a 2025 case-control study demonstrating that higher DII scores were associated with increased odds of polycystic ovary syndrome, even after adjusting for multiple confounders [78].
Table 3: DII Associations with Health Outcomes Across Recent Studies
| Health Outcome | Study Design | Population | Key Finding | Citation |
|---|---|---|---|---|
| Lung Cancer | Prospective cohort | 189,561 participants | Highest DII tertile: 17% increased risk (HR: 1.17, 95% CI: 1.00-1.36) [23] | [23] |
| Parkinson's Disease | Meta-analysis | 326,751 participants | Healthy/anti-inflammatory patterns: 24% reduced risk (RR: 0.76, 95% CI: 0.65-0.91) [4] | [4] |
| Polycystic Ovary Syndrome | Case-control | 200 women | Higher DII associated with increased PCOS odds (OR: 2.82, 95% CI: 1.10-5.60) [78] | [78] |
| Erectile Dysfunction | Cross-sectional | 1,488 men | DII independently associated with ED (OR: 1.07, 95% CI: 1.03-1.11) [76] | [76] |
| Metabolic Syndrome | Systematic review | Not specified | DII useful for understanding diet-inflammation relationship in obesity [74] | [74] |
Interventional Evidence
Randomized controlled trials provide further support for the biological validity of the DII framework. A systematic review and meta-analysis of 22 RCTs found that the Mediterranean diet—a naturally anti-inflammatory pattern—produced the most substantial reductions in inflammatory biomarkers including IL-6, IL-1β, and CRP [77]. This confirms that dietary interventions targeting inflammatory pathways can successfully modulate biomarkers implicated in the DII.
Practical Implementation and Research Applications
Methodological Protocol for DII Implementation
Implementing the DII in research involves a structured process:
1. Dietary Assessment: Collect dietary intake data using validated food frequency questionnaires, 24-hour recalls, or food records. The DII can be computed from various dietary assessment tools, though consistency within a study is crucial [76].
2. Data Processing: Link food consumption data to nutrient composition using appropriate databases. The DII can be calculated from varying numbers of dietary parameters (as few as 27), though more comprehensive assessment improves accuracy [76].
3. DII Calculation:
- For each dietary parameter, calculate a z-score by comparing individual intake to a global standard mean and standard deviation [76]
- Convert the z-score to a percentile value
- Multiply by the respective inflammatory effect score
- Sum across all parameters to derive the overall DII score [76]
4. Statistical Analysis: DII can be analyzed as continuous or categorical variable (tertiles, quartiles, or quintiles). Cox proportional hazards models, logistic regression, or linear regression can be used depending on the outcome [23].
5. Interpretation: Lower DII scores indicate anti-inflammatory diets, while higher scores indicate pro-inflammatory diets [75].
Research Reagent Solutions and Methodological Tools
Table 4: Essential Methodological Components for DII Research
| Research Component | Function/Description | Implementation Example |
|---|---|---|
| FFQ Validation | Ensures accurate dietary assessment | Use of validated semi-quantitative FFQs with established reliability [73] |
| Biomarker Assays | Objective validation of inflammatory status | High-sensitivity CRP, IL-6, TNF-α measurements [73] [77] |
| Global Reference Database | Standardized comparison for DII calculation | Reference values from 11 populations worldwide [76] |
| Inflammatory Effect Scores | Weighting of dietary components | Literature-derived scores for 45 food parameters [74] |
| Statistical Packages | DII calculation and analysis | R, SAS, or STATA code for implementing DII algorithm [76] |
| Covariate Assessment | Control for confounding factors | Standardized collection of BMI, physical activity, smoking status [78] |
The Dietary Inflammatory Index represents a sophisticated a priori tool that bridges nutritional epidemiology and molecular pathophysiology. By quantifying the inflammatory potential of diet based on established biological mechanisms, the DII provides a standardized approach for investigating diet-disease relationships across diverse populations. The robust association between DII scores and various health outcomes—from cancer to neurodegenerative conditions—underscores the fundamental role of inflammation as a mediating pathway between diet and health.
For researchers and drug development professionals, the DII offers several distinct advantages: standardized implementation across populations, hypothesis-driven mechanistic insights, and practical utility for patient stratification in clinical trials. As precision medicine advances, the DII provides a valuable tool for developing targeted nutritional interventions and personalized dietary recommendations based on individual inflammatory responses to diet.
Interpreting 'Healthy' and 'Western' Patterns Across Diverse Studies
Dietary pattern analysis represents a fundamental shift in nutritional epidemiology, moving beyond isolated nutrients to evaluate the cumulative and synergistic effects of foods consumed in combination. This approach is typically categorized into two distinct methodological paradigms: a priori and a posteriori analysis [11]. A priori methods use predefined scores or indices to assess adherence to a dietary pattern considered "ideal" based on existing scientific evidence or dietary guidelines. In contrast, a posteriori methods employ statistical techniques to derive dietary patterns directly from the consumption data of a study population without predetermined hypotheses about what constitutes a "healthy" diet [11] [10]. This technical guide examines how these methodological approaches identify and characterize 'Healthy' and 'Western' dietary patterns across diverse populations and studies, providing researchers with a framework for interpreting pattern-specific findings within the context of their own investigations.
The stability of both methodological approaches has been demonstrated in research, with studies showing consistent pattern identification across short-term intervals when the same methodology is reapplied [10]. However, the application of these patterns across different populations requires careful interpretation, as the same pattern label may reflect substantially different food combinations depending on cultural, geographic, and socioeconomic contexts [11].
Methodological Foundations: A Priori vs. A Posteriori Approaches
A Priori Dietary Pattern Analysis
A priori methods operationalize dietary quality through predefined scoring systems based on current nutritional science. These indices evaluate adherence to dietary patterns associated with favorable health outcomes, such as the Mediterranean diet or the Dietary Approaches to Stop Hypertension (DASH) pattern [10]. Common a priori indices include the Alternative Healthy Eating Index (AHEI), Mediterranean Diet Score (MDS), and various empirically developed indices such as the Dietary Inflammatory Index [11].
A critical consideration in applying a priori methods across diverse populations is the potential for limited score variability when the predefined criteria do not align with local consumption patterns. For instance, in Australian populations, most participants received top scores for trans-fatty acid intake according to the AHEI because baseline intakes were substantially lower than in the U.S. population for which the index was developed [11]. This highlights the importance of validating and potentially modifying scoring criteria when applying a priori patterns to new populations.
A Posteriori Dietary Pattern Analysis
A posteriori methods use statistical techniques to identify prevailing food consumption patterns within a specific dataset, without preconceived notions of what constitutes a "healthy" diet [11]. The most common approaches include:
- Principal Component Analysis (PCA): Reduces food consumption data into patterns based on intercorrelations between food items or groups [79].
- Factor Analysis: Similar to PCA but based on underlying latent variables.
- Cluster Analysis: Groups individuals with similar dietary habits [11].
- Reduced Rank Regression (RRR): Identifies patterns that explain variation in response variables related to specific health outcomes [11].
- Treelet Transform (TT): A newer dimension reduction method combining features of PCA and cluster analysis [11].
The stability of a posteriori patterns improves when analysis uses food groups rather than individual food items, with one study finding that food groups explained approximately 45% of dietary intake variability compared to 24% for food items [10].
Table 1: Key Methodological Approaches in Dietary Pattern Analysis
| Method Type | Approach | Common Techniques | Primary Output |
|---|---|---|---|
| A Priori | Hypothesis-driven; tests adherence to predefined "ideal" diet | Diet quality indices (AHEI, MDS, DASH); Scores based on dietary recommendations | Single score or index value representing degree of adherence |
| A Posteriori | Data-driven; identifies existing patterns in population | PCA, Factor Analysis, Cluster Analysis, RRR | Patterns derived from consumption data, often labeled post-hoc based on component foods |
Characterizing 'Healthy' and 'Western' Dietary Patterns
Defining Pattern Characteristics
Across diverse studies and populations, 'Healthy' and 'Western' dietary patterns demonstrate consistent characteristics despite variations in specific food components. These patterns have been identified using both a priori and a posteriori methods, though the specific food combinations may reflect local dietary contexts.
'Healthy' Dietary Patterns are consistently characterized by higher intakes of fruits, vegetables, whole grains, nuts, legumes, and unsaturated fats [80] [17]. These patterns are associated with improved nutrient profiles including higher fiber, folate, vitamins C and B6, calcium, iron, magnesium, and zinc [80]. In a study of older adults in Alabama, a "More healthful" dietary pattern showed these characteristics and was associated with lower energy density and higher Healthy Eating Index-2005 scores [80]. Similarly, a "health-conscious" pattern identified in an Austrian study was characterized by more favorable nutrient profiles including higher PUFA and dietary fiber [79].
'Western' Dietary Patterns typically feature higher consumption of red and processed meats, refined grains, starchy vegetables, fried foods, and high-fat dairy products [80] [79]. The nutrient profiles associated with these patterns include higher saturated fat, trans fats, sodium, and lower dietary fiber and micronutrient density [80]. In the global context, a westernized dietary pattern identified through PCA of food availability data was composed of energy-dense and processed foods, foods of animal origin, and alcoholic beverages, though it also included some vegetables, fruits, and nuts [81].
Health Outcomes Association
Strong evidence associates these dietary patterns with significant health outcomes. A 2025 study examining eight dietary patterns in relation to healthy aging found higher adherence to healthy patterns was associated with 45-86% greater odds of healthy aging, which encompassed cognitive, physical, and mental health domains, as well as freedom from chronic diseases at age 70 [17]. The AHEI showed the strongest association, followed by empirically developed indices for hyperinsulinemia and inflammation [17].
Table 2: Dietary Pattern Associations with Health Outcomes Across Studies
| Health Outcome | 'Healthy' Pattern Association | 'Western' Pattern Association | Supporting Evidence |
|---|---|---|---|
| Healthy Aging | OR: 1.45-1.86 for highest vs. lowest adherence [17] | Inverse association | Prospective cohorts (N=105,015) followed 30 years |
| Type 2 Diabetes | Inverse association with "traditional southern" pattern (rice, seafood) [11] | Positive association with "modern high-wheat" pattern [11] | Meta-analysis of 10 cohort studies |
| Cardiovascular Risk | "Balanced" pattern inversely associated with cIMT [11] | "Animal protein" pattern positively associated with cIMT [11] | Study in rural Bangladesh |
| Body Composition | Lower odds of overweight/obesity and body fat percentage [79] | Higher odds of overweight/obesity and body fat percentage [79] | Cross-sectional study (n=463) |
| Mental Health | OR: 1.37-2.03 for intact mental health [17] | Associations with depression, anxiety, psychological distress [11] | Multiple observational studies |
Methodological Protocols for Dietary Pattern Analysis
Data Collection and Preprocessing
Robust dietary pattern analysis requires meticulous data collection and preprocessing. The following protocols represent best practices derived from multiple studies:
Dietary Assessment Methods:
- 24-Hour Recalls: Multiple unannounced 24-hour recalls provide detailed quantitative data on food consumption. Studies typically use 2-3 recalls to account for day-to-day variation [80] [79].
- Food Frequency Questionnaires (FFQ): Comprehensive FFQs with 76+ items capture habitual dietary intake over longer periods, though they may be less precise for quantitative estimates [10].
- Food Group Aggregation: Individual food items are aggregated into nutritionally meaningful food groups (typically 13-40 groups) based on culinary use and nutrient profile [80] [79].
Data Standardization:
- Energy adjustment using residuals method or density approach (servings per 1000 kcal)
- Standardization of food group servings based on Dietary Guidelines or FDA serving sizes
- Handling of implausible energy reporting using established cut-offs [80]
Statistical Analysis Procedures
A Posteriori Pattern Derivation:
- Principal Component Analysis: Varimax rotation typically applied to achieve simpler structure; components retained based on eigenvalue >1, scree plot examination, and interpretability [79] [81].
- Factor Analysis: Similar to PCA but based on common variance; used to identify latent constructs underlying food consumption patterns.
- Cluster Analysis: k-means, Ward's method, or Gaussian mixed models used to group individuals with similar dietary patterns [11].
- Pattern Labeling: Derived patterns are labeled post-hoc based on examination of food groups with high factor loadings (>|0.2| typically considered meaningful).
A Priori Pattern Application:
- Predefined scoring algorithms applied to food consumption data
- Cut-points determined based on population-specific medians or absolute intake values
- Validation against nutrient profiles or health outcomes expected to associate with the pattern
Contextual Factors Influencing Pattern Interpretation
Geographic and Cultural Variations
The interpretation of 'Healthy' and 'Western' patterns requires careful consideration of geographic and cultural context. Research demonstrates that similarly labeled patterns may reflect substantially different food combinations across populations:
- Traditional Patterns: In an Iranian study, a "traditional" pattern differed substantially from a similarly named pattern in Australian populations, reflecting distinct foods and showing different associations with mental health outcomes [11].
- Regional Adaptations: The Mediterranean diet pattern shows differential associations with diabetes incidence between European and U.S. studies, potentially because even the most Mediterranean-style diets in the U.S. may not reach the characteristic food intake levels of traditional Mediterranean populations [11].
- Global Westernization: At the global level, a westernized dietary pattern identified through food availability data is associated with income, urbanization, and trade liberalization, though the specific composition varies by region [81].
Socioeconomic Determinants
Socioeconomic factors significantly influence dietary patterns and their health associations:
- Pattern Adherence: Higher diet quality shows stronger associations with healthy aging in populations with lower socioeconomic status and less favorable lifestyle factors [17].
- Gender and Ethnic Disparities: In older Alabama adults, female gender and non-Hispanic white race were the strongest predictors of better diet quality, highlighting potential disparities in dietary pattern adherence [80].
- Economic Development: The westernized dietary pattern identified globally is strongly associated with income level, urbanization, and trade liberalization, while other patterns show less economic association [81].
Research Reagent Solutions for Dietary Pattern Studies
Table 3: Essential Methodological Components for Dietary Pattern Research
| Research Component | Function & Purpose | Examples & Specifications |
|---|---|---|
| Dietary Assessment Tools | Quantify food and nutrient intake | 24-hour recall protocols; Food Frequency Questionnaires (76+ items); Food record forms |
| Food Composition Databases | Convert food consumption to nutrient data | USDA Food Composition Database; German BLS (version 3.02); Country-specific databases |
| Statistical Software Packages | Implement pattern derivation algorithms | SAS (PCA, cluster analysis); R (factoextra, cluster packages); Latent Gold (FMM) |
| Dietary Pattern Indices | Standardized a priori scoring | AHEI, MED, DASH, MIND scoring algorithms; Population-specific adaptations |
| Food Grouping Systems | Aggregate individual foods into meaningful categories | 13-40 food groups based on culinary use and nutrient profile; Standardized serving sizes |
The interpretation of 'Healthy' and 'Western' dietary patterns across diverse studies requires careful attention to methodological approaches, population characteristics, and contextual factors. Both a priori and a posteriori methods provide valuable, complementary insights into dietary behaviors and their health implications.
For researchers, selection of appropriate methodological approaches should align with study objectives: a priori methods for testing specific dietary hypotheses, and a posteriori methods for exploratory analysis of prevailing consumption patterns. Critical considerations include population representativeness, cultural appropriateness of dietary assessment tools, and potential confounding by socioeconomic and lifestyle factors.
Future research should continue to refine standardized approaches for dietary pattern analysis while allowing sufficient flexibility for population-specific adaptations. Integration of multi-omics approaches with dietary pattern analysis may provide deeper understanding of biological mechanisms linking diet to health outcomes. Ultimately, a nuanced interpretation of dietary patterns that acknowledges methodological and contextual influences will strengthen the evidence base for dietary recommendations and interventions across diverse populations.
Synthesizing Evidence for Translation into Public Health Guidelines
The translation of nutritional science into public health policy represents a critical juncture in improving population health. Central to this process is the rigorous synthesis of scientific evidence on dietary patterns—the combinations of foods and beverages consumed—and their relationship to health outcomes. This synthesis occurs primarily through two distinct methodological frameworks: a priori and a posteriori dietary pattern analysis [26]. A priori approaches use predefined indices based on existing dietary guidelines or scientific evidence, such as the Mediterranean Diet Score or Dietary Inflammatory Index (DII), which test hypotheses about how specific dietary patterns influence health [23]. In contrast, a posteriori methods, including principal component analysis and factor analysis, derive dietary patterns empirically from consumption data without predefined hypotheses, revealing actual population eating habits that can then be linked to disease risk [4] [23].
The comparative strength of these approaches was demonstrated in a study predicting acute coronary syndrome and ischemic stroke, which found that both methodologies achieved statistically equivalent classification accuracy across multiple machine learning algorithms [26]. This suggests these approaches offer complementary rather than competing evidence for guideline development. Understanding this methodological landscape is essential for researchers, policymakers, and drug development professionals who must interpret nutritional evidence for application in public health guidelines, pharmaceutical development, and clinical practice.
Methodological Foundations of Dietary Pattern Analysis
A Priori Dietary Patterns: Theory-Driven Approach
A priori dietary patterns are characterized by their hypothesis-driven nature, building upon existing nutritional knowledge and scientific evidence. These approaches operationalize dietary guidance into quantifiable scores that reflect adherence to predefined ideal patterns. The Mediterranean Diet Score exemplifies this approach, evaluating consumption of foods consistent with traditional Mediterranean eating patterns (e.g., high fruits, vegetables, legumes, whole grains, fish, and olive oil) with points assigned based on adherence to target intake levels [26]. Similarly, the Dietary Inflammatory Index (DII) quantifies the inflammatory potential of diet based on extensive literature review of how dietary components affect inflammatory biomarkers [23].
The development process for a priori patterns typically involves:
- Theoretical Foundation: Establishing a basis in existing scientific literature or cultural eating patterns
- Component Selection: Identifying relevant food groups, nutrients, or dietary components
- Scoring System: Creating an algorithm that quantifies adherence
- Validation: Testing the index against health outcomes or biomarkers
A key advantage of a priori methods is their direct relevance to dietary guidance—they test specific hypotheses about how theoretically optimal patterns influence health. This makes them particularly valuable for informing public health policies, as they directly evaluate the potential impact of recommended dietary patterns.
A Posteriori Dietary Patterns: Data-Driven Approach
A posteriori dietary patterns emerge empirically from dietary consumption data using multivariate statistical techniques to identify actual eating patterns within populations. The most common method is principal component analysis (PCA) or factor analysis, which reduces numerous food items into a smaller number of patterns based on correlation structures [23]. For example, a 2024 study of 189,561 UK Biobank participants identified three posteriori patterns: "fruits and vegetables," "cereals and processed foods," and "meat" dietary patterns [23].
The analytical process for deriving a posteriori patterns includes:
- Data Collection: Using 24-hour recalls, food frequency questionnaires, or food records
- Variable Aggregation: Grouping individual foods into meaningful food groups
- Factor Analysis: Applying statistical dimension reduction techniques
- Interpretation: Naming patterns based on foods with high factor loadings
- Validation: Establishing reliability through split-sample or cross-validation techniques
These methods offer the advantage of reflecting actual population eating habits without theoretical presuppositions, potentially identifying novel patterns that may not align with established guidelines. However, they are specific to the population studied and may not be generalizable across different demographic or cultural groups.
Comparative Methodological Characteristics
Table 1: Fundamental Characteristics of A Priori and A Posteriori Dietary Patterns
| Characteristic | A Priori Patterns | A Posteriori Patterns |
|---|---|---|
| Theoretical basis | Hypothesis-driven, based on prior knowledge | Exploratory, data-driven |
| Method examples | Mediterranean Diet Score, DII, HEI | Principal component analysis, factor analysis, cluster analysis |
| Primary strength | Directly testable against health outcomes | Reflects actual population eating habits |
| Limitations | May miss important population-specific patterns | Population-specific, less generalizable |
| Interpretation | Based on predefined criteria | Based on statistical correlations |
| Guideline relevance | High (directly tests recommended patterns) | Variable (may reveal unexpected patterns) |
Quantitative Evidence Synthesis: Disease-Specific Associations
Neurodegenerative Disease Evidence
A comprehensive meta-analysis of observational studies through January 2025 examined associations between dietary patterns and Parkinson's disease risk across 11 studies with 326,751 participants and 2,524 cases [4]. The analysis revealed significant protective associations for several healthy dietary patterns, with the Mediterranean diet demonstrating an 13% risk reduction (RR = 0.87; 95%CI: 0.78–0.97), while healthy dietary indices and healthy dietary patterns both showed 24% risk reductions (RR = 0.76; 95%CI: 0.65–0.91 and RR = 0.76; 95%CI: 0.62–0.93, respectively) [4]. Conversely, Western dietary patterns characterized by high consumption of red and processed meats, refined grains, and high-fat dairy products were associated with a 54% increased risk (RR = 1.54; 95%CI: 1.10–2.15) [4].
Cancer and Cardiovascular Evidence
A prospective cohort study of 189,561 UK Biobank participants with median 9.45 years follow-up examined dietary patterns and lung cancer risk, identifying 1,041 incident cases [23]. The study integrated both a priori (DII) and a posteriori (factor analysis) approaches, finding that higher DII scores (indicating pro-inflammatory diets) were associated with 17% increased lung cancer risk (HR T3 vs. T1: 1.17; 95%CI: 1.00, 1.36) [23]. The a posteriori fruits and vegetables pattern showed a 22% risk reduction (HR T3 vs. T1: 0.78; 95%CI: 0.67, 0.91), while the meat pattern was associated with 18% increased risk (HR T3 vs. T1: 1.18; 95%CI: 1.02, 1.37) [23]. The cereals and processed foods pattern showed no significant association [23].
For cardiovascular disease, a case-control study applied six classification algorithms to compare a priori and a posteriori pattern predictive accuracy for acute coronary syndrome (ACS) and ischemic stroke [26]. The a priori approach using MedDietScore achieved C-statistics of 0.807 for ACS and 0.767 for stroke using multiple logistic regression, while a posteriori patterns achieved 0.827 for ACS and 0.780 for stroke, demonstrating statistically equivalent predictive accuracy between approaches [26].
Table 2: Disease Risk Associations for A Priori and A Posteriori Dietary Patterns
| Disease Outcome | Dietary Pattern Type | Specific Pattern | Risk Estimate (Highest vs. Lowest) | Confidence Interval |
|---|---|---|---|---|
| Parkinson's Disease | A priori | Mediterranean diet | RR = 0.87 | 95%CI: 0.78–0.97 |
| A priori | Healthy dietary index | RR = 0.76 | 95%CI: 0.65–0.91 | |
| A posteriori | Healthy dietary pattern | RR = 0.76 | 95%CI: 0.62–0.93 | |
| A posteriori | Western dietary pattern | RR = 1.54 | 95%CI: 1.10–2.15 | |
| Lung Cancer | A priori | Dietary Inflammatory Index (T3 vs. T1) | HR = 1.17 | 95%CI: 1.00, 1.36 |
| A posteriori | Fruits and vegetables pattern | HR = 0.78 | 95%CI: 0.67, 0.91 | |
| A posteriori | Meat pattern | HR = 1.18 | 95%CI: 1.02, 1.37 | |
| A posteriori | Cereals and processed foods | HR = 0.97 | 95%CI: 0.83, 1.12 | |
| ACS Prediction | A priori | MedDietScore | C-statistic = 0.807 | MLR algorithm |
| A posteriori | Principal components | C-statistic = 0.827 | MLR algorithm | |
| Stroke Prediction | A priori | MedDietScore | C-statistic = 0.767 | MLR algorithm |
| A posteriori | Principal components | C-statistic = 0.780 | MLR algorithm |
Methodological Protocols for Evidence Generation
Systematic Review and Meta-Analysis Protocol
The methodological protocol for synthesizing evidence on dietary patterns and disease relationships follows rigorous systematic review standards, as demonstrated in the Parkinson's disease meta-analysis [4]:
Search Strategy: Comprehensive literature search across multiple electronic databases (PubMed, Web of Science, Scopus, China National Knowledge Infrastructure) using predefined search terms combining dietary pattern terminology ("dietary pattern," "eating pattern," "food pattern," "diet indices") with disease-specific terms ("Parkinson's disease," "Parkinson disease") [4]. No date or language restrictions are typically applied to maximize evidence capture.
Study Selection Criteria: Inclusion criteria encompass observational studies (cohort, case-control, cross-sectional) in human populations examining whole dietary patterns in relation to disease outcomes, with risk estimates (odds ratios, relative risks, hazard ratios) and corresponding confidence intervals [4]. Exclusion criteria typically remove intervention studies, reviews, editorials, and studies not reporting applicable effect measures.
Data Extraction and Quality Assessment: Standardized extraction of study characteristics (design, population, cases, dietary assessment method, covariates) and risk estimates. Quality assessment using validated tools such as the Newcastle-Ottawa Scale for observational studies, evaluating selection, comparability, and outcome assessment [4].
Statistical Analysis: Calculation of pooled risk estimates using random-effects models, assessment of heterogeneity via Cochran's Q test and I² statistic, and investigation of potential sources of heterogeneity through subgroup and sensitivity analyses [4].
Dietary Assessment and Pattern Derivation Protocols
Dietary Assessment Methods: Most large-scale studies employ food frequency questionnaires (FFQs), 24-hour dietary recalls, or food records. The UK Biobank study used 24-hour dietary recall questionnaires administered at baseline [23], while case-control studies often utilize validated FFQs specifically designed for the population under study.
A Priori Pattern Implementation: Implementation requires predefined scoring criteria based on existing evidence. For Mediterranean diet scores, this typically involves assigning points for consumption above population medians for beneficial components (fruits, vegetables, legumes, fish) and below medians for detrimental components (meat, dairy), with summary scores categorized into adherence levels [26].
A Posteriori Pattern Derivation: Statistical derivation involves multiple standardized steps: (1) aggregation of individual foods into food groups; (2) application of principal component analysis with varimax rotation; (3) determination of number of factors to retain based on eigenvalues (>1.0), scree plot examination, and interpretability; (4) calculation of pattern scores for each participant using regression methods; and (5) categorization of scores into quantiles for analysis [23]. The UK Biobank analysis demonstrated this approach, identifying three patterns explaining 28.54% of total variance in food group intake [23].
Evidence Integration in Guideline Development
The Dietary Guidelines Advisory Committee employs systematic evidence review protocols complemented by food pattern modeling to translate evidence into dietary recommendations [82]. This process includes:
Food Pattern Modeling: A methodology that illustrates how changes to amounts or types of foods in existing dietary patterns affect nutrient needs meeting, used to develop quantitative dietary patterns [82]. The 2025 Advisory Committee conducted nine food pattern modeling analyses addressing specific questions about modifying food group quantities within healthy dietary patterns [82].
Systematic Review Integration: Evidence from systematic reviews of a priori and a posteriori dietary pattern studies informs recommendations, with the Committee considering "findings from systematic reviews, data analysis, and/or food pattern modeling analyses" when determining potential updates to USDA Dietary Patterns [82].
Diagram 1: Evidence Integration Pathway for Dietary Guidelines. This workflow illustrates how evidence from multiple methodological approaches converges to inform public health guidelines.
Research Reagents and Methodological Tools
Table 3: Essential Methodological Tools for Dietary Pattern Research
| Tool Category | Specific Tool/Technique | Primary Function | Application Context |
|---|---|---|---|
| Dietary Assessment | Food Frequency Questionnaire (FFQ) | Assess habitual dietary intake | Both a priori and a posteriori approaches |
| 24-Hour Dietary Recall | Capture recent dietary intake | A posteriori pattern derivation | |
| Food Records | Detailed prospective intake recording | Validation studies | |
| Statistical Analysis | Principal Component Analysis | Derive empirical dietary patterns | A posteriori pattern identification |
| Factor Analysis | Identify underlying food combination patterns | A posteriori approach | |
| Multiple Logistic Regression | Test diet-disease associations | Both approaches | |
| Cox Proportional Hazards | Model time-to-event data | Prospective studies | |
| A Priori Indices | Mediterranean Diet Score | Quantify Mediterranean diet adherence | A priori hypothesis testing |
| Dietary Inflammatory Index (DII) | Assess diet inflammatory potential | A priori mechanistic pathways | |
| Healthy Eating Index | Evaluate adherence to dietary guidelines | A priori policy relevance | |
| Machine Learning Algorithms | Support Vector Machines | Pattern classification | Comparative accuracy assessment |
| Artificial Neural Networks | Complex pattern recognition | Nonlinear relationship detection | |
| Naïve Bayes Classifiers | Probabilistic classification | Risk prediction models | |
| Quality Assessment | Newcastle-Ottawa Scale | Quality assessment of observational studies | Evidence synthesis |
| Cochrane Risk of Bias Tool | Systematic review quality assessment | Meta-analyses |
Diagram 2: Methodological Workflow for A Priori and A Posteriori Dietary Pattern Analysis. This diagram illustrates the parallel processes of hypothesis-driven (a priori) and data-driven (a posteriori) approaches to dietary pattern research, which converge at evidence synthesis for guideline development.
The synthesis of evidence from both a priori and a posteriori dietary pattern analyses provides a robust foundation for developing evidence-based public health guidelines. Each methodological approach offers complementary strengths: a priori patterns directly test hypotheses based on existing scientific knowledge and are therefore highly relevant for policy recommendations, while a posteriori patterns reflect actual population eating habits and may identify novel associations not captured by predefined indices [4] [26] [23].
The convergence of evidence across multiple methodological approaches strengthens confidence in dietary recommendations. For example, the consistent findings that plant-forward patterns (Mediterranean diet, fruits and vegetables pattern) are associated with reduced risk of Parkinson's disease, lung cancer, and cardiovascular disease, while Western and meat-based patterns increase risk, provides compelling evidence for policy action [4] [23]. Future methodological development should focus on integrating these approaches, applying advanced machine learning techniques, and ensuring that evidence synthesis processes remain "universally viewed as valid, evidence-based, and free of bias" to maximize public health impact [83].
Conclusion
A priori and a posteriori dietary pattern analyses are complementary methodologies that provide powerful, holistic insights into the diet-disease relationship. While a priori scores are invaluable for testing hypotheses against established dietary guidelines, a posteriori methods uncover real-world eating behaviors within specific populations. The choice between them should be guided by the research objective, with a growing emphasis on hybrid methods and standardized applications to enhance reproducibility and comparability. For biomedical research, this evidence is crucial for developing targeted nutritional interventions and drugs, informing public health policy, and advancing a more nuanced understanding of diet as a modifiable risk factor in chronic disease prevention and management.
References
- 1. Conceptual difference between hypothesis-driven and data ... [https://ngwenfa.wordpress.com/2024/06/30/conceptual-difference-between-hypothesis-driven-and-data-driven-research/]
- 2. Data vs hypothesis driven research: the false dichotomy [https://kamounlab.medium.com/data-vs-hypothesis-driven-research-the-false-dichotomy-2b026e5007e6]
- 3. A posteriori dietary patterns better explain variations of the ... [https://www.sciencedirect.com/science/article/pii/S0002916522001526]
- 4. Adherence to a priori and a posteriori dietary patterns and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12105580/]
- 5. Advances in dietary pattern analysis in nutritional ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8572214/]
- 6. Dietary Pattern Analysis - an overview [https://www.sciencedirect.com/topics/food-science/dietary-pattern-analysis]
- 7. A review of statistical methods for dietary pattern analysis [https://nutritionj.biomedcentral.com/articles/10.1186/s12937-021-00692-7]
- 8. Dietary patterns – A scoping review for Nordic Nutrition ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11075466/]
- 9. Unveiling Dietary Complexity: A Scoping Review and ... [https://www.mdpi.com/2072-6643/17/20/3261]
- 10. Short-term stability of dietary patterns defined a priori or a ... [https://www.sciencedirect.com/science/article/abs/pii/S0378512210004494]
- 11. What can we learn from dietary pattern analysis? - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC10273249/]
- 12. Advances in methods for characterizing dietary patterns [https://pmc.ncbi.nlm.nih.gov/articles/PMC11213084/]
- 13. Dietary patterns analysis using data mining method. An ... [https://www.sciencedirect.com/science/article/abs/pii/S0169260711003282]
- 14. Comparative analysis of a-priori and a-posteriori dietary ... [https://pubmed.ncbi.nlm.nih.gov/24080079/]
- 15. Review of a priori dietary quality indices in relation to their ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6130981/]
- 16. Perspective: The Application of A Priori Diet Quality Scores ... [https://www.sciencedirect.com/science/article/pii/S2161831322002319]
- 17. Optimal dietary patterns for healthy aging | Nature Medicine [https://www.nature.com/articles/s41591-025-03570-5]
- 18. 8c. Dietary Guidelines and Assessing Diet Quality [https://nutritionalassessment.org/diet/]
- 19. Diet quality indices and their associations with health-related ... [https://nutritionj.biomedcentral.com/articles/10.1186/s12937-020-00632-x]
- 20. The association of priori and posteriori dietary patterns with ... [https://translational-medicine.biomedcentral.com/articles/10.1186/s12967-021-02704-w]
- 21. Perceptions of the Three Dietary Patterns of the 2020 ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12608769/]
- 22. Adherence to a priori and a posteriori dietary patterns and ... [https://www.frontiersin.org/journals/nutrition/articles/10.3389/fnut.2025.1600955/full]
- 23. A cohort study on the association of dietary inflammatory ... [https://www.nature.com/articles/s41598-025-15970-1]
- 24. Pre- and post-diagnosis dietary patterns and overall survival ... [https://bmccancer.biomedcentral.com/articles/10.1186/s12885-025-13610-5]
- 25. Do dietary patterns influence cognitive function in old age? [https://www.sciencedirect.com/science/article/pii/S1041610224014340]
- 26. Comparative analysis of a-priori and a-posteriori dietary ... [https://www.sciencedirect.com/science/article/abs/pii/S093336571300122X]
- 27. Development and Validation of the Short Healthy Eating ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7551037/]
- 28. Healthy Eating Index (HEI) [https://www.fns.usda.gov/cnpp/healthy-eating-index-hei]
- 29. Exploring the Validity of the 14-Item Mediterranean Diet ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7601687/]
- 30. A Short Screener Is Valid for Assessing Mediterranean Diet ... [https://www.sciencedirect.com/science/article/pii/S0022316622029649]
- 31. 2025 Best Diet Wins Gold for Wellness and Disease ... [https://www.msm.edu/RSSFeedArticles/2025/January/2025-Best-Diet.php]
- 32. Difference Between Factor Analysis and Principal ... [https://www.geeksforgeeks.org/machine-learning/difference-between-factor-analysis-and-principal-component-analysis/]
- 33. Factor Analysis [https://link.springer.com/chapter/10.1007/978-3-658-47931-2_7]
- 34. Comparison Between Principal Components and Factor ... [https://www.sciencepg.com/article/10.11648/j.ijsd.20220804.11]
- 35. Exploring the association of dietary patterns with the risk ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11077459/]
- 36. A Posteriori Dietary Patterns: How Many Patterns to Retain? [https://www.sciencedirect.com/science/article/pii/S0022316622009658]
- 37. A comparison of principal component analysis, reduced-rank ... [https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-024-02298-z]
- 38. Associations between dietary patterns derived using ... [https://pubmed.ncbi.nlm.nih.gov/40916137/]
- 39. Are Major Dietary Patterns Reproducible Within a Country? [https://www.sciencedirect.com/science/article/pii/S216183132200391X]
- 40. Dietary patterns derived by reduced rank regression ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11519099/]
- 41. The association between dietary patterns derived by reduced ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6132244/]
- 42. Exploring dietary patterns by using the treelet transform [https://pubmed.ncbi.nlm.nih.gov/21474587/]
- 43. Using reduced rank regression methods to identify dietary ... [https://www.cambridge.org/core/journals/british-journal-of-nutrition/article/using-reduced-rank-regression-methods-to-identify-dietary-patterns-associated-with-obesity-a-crosscountry-study-among-european-and-australian-adolescents/F9C201AF1EB0ED10A762BE1FC6FA8528]
- 44. Tutorial on statistical data reduction methods for exploring ... [https://www.sciencedirect.com/science/article/abs/pii/S2405457723021460]
- 45. FFQ [https://www.epic-norfolk.org.uk/about-epic-norfolk/nutritional-methods/ffq/]
- 46. Dietary Assessment by Pattern Recognition: a Comparative ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10550800/]
- 47. ASA24® Dietary Assessment Tool | EGRP/DCCPS/NCI/NIH [https://epi.grants.cancer.gov/asa24/]
- 48. Dietary assessment in intermittent fasting: validation of a ... [https://pubmed.ncbi.nlm.nih.gov/40791239/]
- 49. Data Analysis for the 2025 Guidelines Committee Report [https://www.dietaryguidelines.gov/2025-advisory-committee-report/data-analysis]
- 50. Improving dietary data collection tools for better nutritional ... [https://www.sciencedirect.com/science/article/pii/S2666990022000180]
- 51. Biochemical validation of a food frequency questionnaire ... [https://www.sciencedirect.com/science/article/pii/S0939475325000882]
- 52. Association between a priori and a posteriori dietary patterns ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9947633/]
- 53. The Role of Diet in Women of Childbearing Age [https://www.mdpi.com/2072-6643/17/22/3505]
- 54. Dietary patterns are influenced by socio-demographic ... [https://bmcpublichealth.biomedcentral.com/articles/10.1186/s12889-018-5184-4]
- 55. Tracking of Dietary Patterns between Pregnancy and 6 ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7612407/]
- 56. Which color scale to use when visualizing data [https://www.datawrapper.de/blog/which-color-scale-to-use-in-data-vis]
- 57. Mastering The Art of Data Visualization Color Palettes [https://www.datylon.com/blog/a-guide-to-data-visualization-color-palette]
- 58. Assessment of dietary patterns in nutritional epidemiology [https://www.sciencedirect.com/science/article/pii/S0002916523030356]
- 59. Naturalistic food categories are driven by subjective estimates ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10783799/]
- 60. Reproducibility and research integrity: the role of scientists ... [https://bmcresnotes.biomedcentral.com/articles/10.1186/s13104-021-05875-3]
- 61. Reproducibility of dietary intakes of macronutrients, specific ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6842574/]
- 62. Nutrition Questionnaire Service Center | Department of Nutrition [https://hsph.harvard.edu/department/nutrition/nutrition-questionnaire-service-center/]
- 63. Dietary Patterns within a Population Are More ... [https://www.sciencedirect.com/science/article/pii/S0022316622013384]
- 64. Overview of Dietary Assessment Methods for Measuring ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8338737/]
- 65. A Systematic Review of the Methods Used to Assess and ... [https://www.frontiersin.org/journals/nutrition/articles/10.3389/fnut.2022.892351/full]
- 66. Unveiling Dietary Complexity: A Scoping Review and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12567371/]
- 67. This dietary pattern could save lives and the planet [https://hsph.harvard.edu/news/this-dietary-pattern-could-save-lives-and-the-planet/]
- 68. Review of dietary patterns and gastric cancer risk [https://pmc.ncbi.nlm.nih.gov/articles/PMC10912593/]
- 69. A Priori and a Posteriori Dietary Patterns in Women of ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7598658/]
- 70. Foods and Dietary Intakes and the Risk of Parkinson's ... [https://pubmed.ncbi.nlm.nih.gov/41252180/]
- 71. Impact of dietary patterns on the survival outcomes ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12343251/]
- 72. Models based on dietary nutrients predicting all-cause and ... [https://www.nature.com/articles/s41598-025-88480-9]
- 73. Development and Validation of an Empirical Dietary ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4958288/]
- 74. Scientific basis of dietary inflammatory index (DII) [https://www.sciencedirect.com/science/article/pii/S2667268525000415]
- 75. Understanding The Dietary Inflammatory Index and Its Uses [https://obesitymedicine.org/blog/foods-that-aid-in-stress-relief-and-lowering-inflammation/]
- 76. Associations of dietary inflammatory index and composite ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12170290/]
- 77. Effects of Dietary Patterns on Biomarkers of Inflammation ... [https://www.sciencedirect.com/science/article/pii/S2161831322005312]
- 78. Association between dietary inflammatory index, empirical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12409934/]
- 79. Traditional v. modern dietary patterns among a population in ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10260468/]
- 80. DIETARY PATTERNS AND DIET QUALITY AMONG DIVERSE ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3574872/]
- 81. Worldwide dietary patterns and their association with ... [https://globalizationandhealth.biomedcentral.com/articles/10.1186/s12992-022-00820-w]
- 82. Food Pattern Modeling for the 2025 Advisory Committee ... [https://www.dietaryguidelines.gov/2025-advisory-committee-report/food-pattern-modeling]
- 83. Analysis of the Scientific Methodologies, Review Protocols ... [https://www.ncbi.nlm.nih.gov/books/NBK583913/]